
« Fictions et données » : la tension entre ces deux termes – le premier étroitement associé à l’imaginaire, le second rattaché au réel (non sans problème, on y reviendra) – n’est que l’une des nombreuses manifestations possibles du brouillage entre réel et fiction qui caractérise le moment contemporain de la littérature. Décrié par une partie de la critique, dont Françoise Lavocat qui, dans Faits et fictions, pointe avec justesse la « nécessité cognitive, conceptuelle et politique des frontières de la fiction1 », ce brouillage est pourtant l’une des caractéristiques majeures de la littérature numérique, et se trouve abondamment traité dans les travaux qui lui sont consacrés.
Il faut dire que les œuvres littéraires numériques, de par leur présence dans un espace en ligne, dont le statut ontologique n’est pas si simple à déterminer – tant il empiète sur notre espace dit « réel » ou, du moins, sur notre façon d’habiter le monde2 – occupent une place particulière dans ce débat théorique. De fait, il est essentiel de souligner combien l’étude de la littérature numérique investit nécessairement une tension entre deux conceptions de la création qui s’opposent bien au-delà du champ théorique littéraire depuis déjà plusieurs dizaines d’années : d’une part, une conception représentative où l’œuvre se pose en fenêtre sur le monde, d’autre part une conception performative dans laquelle le geste artistique participe à façonner et à structurer le réel. Cette dernière est centrale dans la théorie de l’éditorialisation3 régulièrement convoquée dans le champ des études littéraires numériques. Ainsi, dans des travaux antérieurs, nous avions même défendu un parti pris radical en affirmant l’idée d’une fusion entre le réel et l’imaginaire :
Le fait de penser le geste de production des contenus numériques comme un geste de production de l’espace nous permet justement d’aller au-delà de l’opposition imaginaire/réel. Les pratiques, les discours et les technologies impliquées dans un geste d’éditorialisation ont comme résultat l’agencement d’un espace tout à fait réel, à savoir l’espace dans lequel nous vivons4.
Selon cette conception, une fiction en ligne serait donc une donnée comme une autre, située sur le même plan ontologique que, par exemple, les horaires de train disponibles via l’API de la SNCF, utilisée par Françoise Chambefort pour réaliser Lucette, gare de Clichy. Pourtant, ces deux paradigmes représentatifs et performatifs semblent s’évertuer à cohabiter au sein des fictions littéraires en ligne, jouant abondamment des effets d’ambiguïté entre réel et fiction – ambiguïté que les théories de l’éditorialisation littéraire, dans leur état actuel, ne creusent sans doute pas assez. C’est pourtant dans cette tension que réside tout l’intérêt de l’écriture littéraire des données : quel statut conférer à un profil numérique dit « fictif » (bot, profil de fiction, etc.), alors même qu’il intervient et converse sur un réseau social avec le profil d’un individu réel ? En quoi un récit géolocalisé peut-il transformer un quartier, en faisant converger ses habitants vers des espaces singuliers ?
En ce qui concerne le rapport entre fiction et données, le problème est redoublé par le statut ontologique problématique des données elles-mêmes, éléments extraits du réel de manière arbitraire, mais qui ont tendance à se substituer au réel, ou du moins à en tenir lieu dans notre imaginaire5. Aussi, la réflexion sur la littérature des données suppose d’abord un déplacement conceptuel : ce que l’on appelle « réel » a changé sous l’effet de sa mise en données. Bachimont évoque même, on le verra, un nouveau régime de connaissance, fondé sur un principe de codification. En toute logique, ce que l’on appelle « fiction » évolue également.
Cet article a pour objectif de décrire et d’analyser certaines de ces mutations de la fiction lorsqu’elle se confronte à la réalité des données, tant sur un plan pratique que théorique. C’est notamment tout l’enjeu du néologisme que je propose, la « captafiction », dont je baliserai les contours à l’aide du projet Anna K de Catherine Lenoble6.
« Captafiction », un néologisme de la littérature numérique, encore ?
La notion de captafiction – alternative à la data-fiction – que j’ajoute à la liste déjà conséquente des néologismes de la littérature numérique est un parti pris conceptuel qui pose l’accent sur la problématique ontologique propre aux données numériques. Pour s’orienter dans cette problématique, il m’apparaît capital de convoquer certains travaux structurants menés ces dernières années dans le champ des sciences humaines et sociales. J’insisterai, en particulier, sur la notion de « capta », grâce à laquelle on peut poser un cadre théorique et méthodologique précieux pour repenser les enjeux de la mimesis littéraire.
Tout d’abord, la notion de « capta » permet de s’abstraire du terme « données », dont il s’agit avant tout déconstruire le faux certificat d’authenticité. C’est désormais un poncif de le dire, et pourtant l’ambiguïté demeure : une donnée numérique n’est pas une émanation brute du réel. Elle est construite, choisie, prélevée en fonction de présupposés ou de postulats parfois clairement énoncés, mais plus souvent inconscients et impensés. C’est d’ailleurs l’un des apports les plus fondamentaux des SHS à la science des données que de proposer une réflexion critique sur le concept de données lui-même, auquel plusieurs alternatives terminologiques ont été proposées : Bruno Latour, notamment, y substitue le terme d’« obtenues7 », tandis que Johana Drucker8 a forgé le terme « capta » auquel je me rallie ici également – j’en détaillerai les raisons précises dans un instant. Fondamentalement, ces alternatives visent à déconstruire l’illusion d’objectivité de la donnée, en la réintégrant dans un paradigme représentationnel – la donnée n’est pas un échantillon du réel, elle en est déjà une remédiation.
Or si la donnée relève en partie d’un paradigme représentationnel, elle n’en fait pas moins bouger les frontières de la représentation. C’est la thèse que défendent Bruno Bachimont et Lise Verlaet, à qui l’on doit une série de travaux récents sur l’ontologie des données. Pour Bruno Bachimont, c’est parce qu’elle est fondamentalement composée de code – code qui, dans son principe, « établit une convention arbitraire entre le réel et sa représentation [et] ne repose pas sur une exigence de conformité avec le réel lors sa création ni de coévolution par la suite9 » – que la donnée implique un nouveau régime de connaissance et de représentation :
« avec les systèmes numériques et le codage de et par l’information, la représentation [de l’époque contemporaine] ne ressemble pas à son origine ni ne covarie de manière nécessaire avec elle, mais en est un codage dont la manipulation calculée n’impose pas que le résultat soit une conséquence du comportement de l’objet ou réalité qui est codée10 ».
En distinguant entre elles successivement les notions de trace, d’enregistrement et de données numériques, qui creusent de l’une à l’autre l’écart entre le réel « brut » (lui-même clairement fantasmé d’ailleurs) et la représentation du réel, Bruno Bachimont et Lise Verlaet soulignent alors l’importance de mettre au point une herméneutique des données capable de reconstruire du sens :
« C’est la raison pour laquelle l’intelligibilité du numérique en passe par l’intelligence des traces et leur herméneutique ou interprétation. Il s’agit de comprendre ce qui se passe quant au sens quand on traite les traces comme des données à mobiliser dans des systèmes numériques, et quels sont les outils, méthodes, concepts permettant de reconstruire un régime du sens, une manière de comprendre et d’interpréter ces traitements11. »
L’hypothèse que je veux défendre ici, c’est que la captafiction, en tant qu’écriture littéraire des données, a vocation à se poser comme l’une des méthodes susceptibles de reconstruire un régime du sens. Or pour y parvenir, il faut sans doute commencer par dépasser l’opposition radicale entre réel et fiction, et adopter un modèle ontologique moins binaire, apte à rendre compte d’une dimension multiple, hétérogène (soit, parfois, contradictoire et conflictuelle) du monde et de nos expériences du réel. C’est notamment sur ce dernier point que le paradigme performatif évoqué plus tôt peut nous aider – sans résoudre toutefois complètement la question.
L’herméneutique des données est également au cœur des travaux de Johanna Drucker12, à qui l’on doit le terme de « capta » mentionné tout à l’heure. La proposition de Johanna Drucker, que je résume brièvement, tout en tâchant d’y rester la plus fidèle possible, s’articule autour du concept d’« interprétation modélisante » que Drucker oppose radicalement à la « visualisation de l’information », conçue comme un simple affichage de données. Ce que Drucker reproche à la visualisation classique, largement répandue aujourd’hui dans les médias et jusque dans les travaux scientifiques, c’est sa tendance à redoubler la tentation objectivante des données, alors même que chaque visualisation devrait d’abord être considérée comme une remédiation de la donnée.
Là où les visualisations ont par ailleurs une fonction souvent illustrative – elles sont largement utilisées comme des outils rhétoriques servant à conforter un argument – Drucker défend la constitution d’une épistémologie visuelle à part entière, dans laquelle l’écriture graphique n’aurait pas seulement vocation à représenter une connaissance existante, mais jouerait également un rôle en tant que mode de production de connaissance.
Cela veut dire qu’une expression graphique pourrait être utilisée pour exposer – ainsi que pour créer – un modèle d’activité interprétative. Cette approche change la relation unidirectionnelle entre les données et l’affichage et la transforme en un échange réciproque13.
Si la littérature n’est pas le terrain de Drucker, son travail est pourtant susceptible d’éclairer en partie le tournant médiatique de la littérature largement redevable des expérimentations numériques. Image du texte, sémiotique du support et dialectique intermédiale participent en effet à la constitution d’une herméneutique un peu particulière, où le sens surgit également des effets de matérialité du texte. Or, cette dimension médiatique, et en particulier graphique, est un aspect essentiel de la captafiction que je vais à présent présenter de manière plus concrète, à travers le cas d’étude offert par le projet Anna K de Catherine Lenoble.
Pour une approche graphique de la littérature des données
Publié en 2016 aux éditions HYX, l’ouvrage Anna K est l’une des productions issues d’un projet artistico-littéraire14, consacré à l’écrivaine Anna Kavan, qui a vécu et publié dans la première partie du xxe siècle. Le projet comprend également une création en ligne, Kavan.land, dont il sera fait mention dans cet article, ainsi qu’une archive offline Kavan.lan, que je laisse en revanche de côté faute d’avoir eu l’occasion de la consulter.
L’analyse que je propose met l’accent sur la dimension graphique de l’écriture des données – depuis leur traitement informatique jusqu’à leur remédiatisation sous forme de visualisation – à travers une perspective éditoriale d’abord attachée à l’image du texte, au sens premier du terme : sa mise en page, sa mise en forme, sa typographie et ses « illustrations ». Il existe évidemment de nombreux travaux de visualisation de données littéraires, ainsi que des travaux sur les enjeux épistémologiques de cette visualisation, mais finalement assez peu d’études sur la visualisation en tant qu’écriture littéraire. Si l’on a déjà beaucoup commenté, en effet, la dimension informatique des écritures numériques (c’est le domaine des critical code studies15), ainsi que leur dimension médiatique (dans le domaine des platform studies16), ou encore leur dimension culturelle et poétique17, on a encore assez peu abordé leur dimension graphique – au sens où le produit l’art de la visualisation.
Or, c’est bien de ce phénomène que témoigne le travail Catherine Lenoble. Le projet Anna K comprend d’abord un dataset, soit un jeu de données collectées par Lenoble autour de la thématique « Anna Kavan », puis un récit, une sorte de biographie-enquête, conçue autour ou à partir d’un ensemble de visualisations des données – lesquelles ont été réalisées en collaboration avec Alexandre Leray et Stéphanie Vilayphiou, membres du collectif Open Source Publishing.
Une première consultation de l’ouvrage révèle une organisation graphique complexe, mêlant plusieurs formes et formats d’écritures, signalés par un travail éditorial et un design singulier :
Figure 1 : Double page de l’ouvrage Anna K (p. 10-11) faisant figurer les différents formats d’écriture (code, langage naturel, graphes). Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.

- une écriture du code dont la police est cependant très éloignée du standard du code informatique, qui plus est présentée ici sous une forme cursive qui a pour effet de désinformatiser le code ;
- une écriture en « langage naturel », reprenant une typographie classique, où alternent cependant différentes « voix », incarnées par un jeu de couleur (gris et vert) ;
- une écriture graphique, qui relève donc de la visualisation informatique, et qui s’appuie comme on le découvre rapidement à la lecture sur le jeu de données établi par l’autrice. Ces graphes reprennent pour la plupart le même jeu de couleur vert / gris (gris pour les liens [egde], vert pour les nœuds [node]). Ils ont été réalisés pour la plupart à l’aide de l’outil open source Graphviz, en collaboration avec le collectif Open Source Publishing.
Quel rôle ces éléments de visualisation viennent-ils jouer dans le projet de Catherine Lenoble ? Se contentent-ils d’ancrer le récit dans le réel ou, du moins, de l’objectiver, un peu comme un document d’archives ou une photographie insérée dans un récit ? Difficile d’échapper aujourd’hui à une forme d’obsession du graphe, que l’on retrouve largement dans les écrits non fictionnels (enquêtes journalistiques, travaux scientifiques, rapports). Difficile également pour le néophyte d’apprécier ces visualisations pour leurs qualités graphiques, voire plastiques, tant les formes que l’on nous présente manquent souvent d’inventivité, au bénéfice d’une intelligibilité (parfois elle-même discutable, d’ailleurs).
Mais si le graphe relève a priori d’un registre didactique, il n’en reste pas moins appréciable pour ses qualités esthétiques. Les travaux déjà mentionnés de Johanna Drucker, mais également d’Edward R. Tufte18, ont démontré le potentiel aussi bien heuristique qu’esthétique de ces formes graphiques, dont les premiers exemples apparaissent bien avant l’ère informatique.
On tiendra dès lors le pari d’une poétique texte/image, fondée sur la data visualisation et participant d’une double herméneutique de la donnée. Tandis que les graphiques présents dans Anna K jouent en partie un rôle de représentation visuelle de données massives (pour nous les rendre intelligibles), je voudrais également démontrer qu’ils renouent avec un acte graphique d’écriture. Leur présence dans l’espace d’inscription qu’est le livre, en particulier, permet de réintroduire une certaine ambiguïté au sein de ces formes généralement conçues comme objectivantes et transparentes. En effet, chez Catherine Lenoble, nous constaterons que les visualisations mettent le lecteur face à un défi interprétatif plutôt ardu, puisqu’un examen attentif a tendance à suggérer des formes imbriquées et ambiguës, tendant vers la figuration ou l’expression symbolique.
Portrait de l’artiste en dataset
L’importance de cette dimension graphique de l’écriture des données à présent clairement établie, revenons-en à la thématique et la méthodologie du projet Anna K. Autrice d’une œuvre au caractère expérimental très marqué et par endroits torturée, Anna Kavan a été parfois comparée à Franz Kafka, et a inspiré plusieurs écrivaines de son époque, notamment Anaïs Nin qui ne cache pas son admiration pour son œuvre. Mais il faut bien l’avouer, Kavan n’a guère connu une incroyable postérité.
Le projet Anna K se conçoit donc d’abord comme une enquête visant à redécouvrir le destin de l’autrice ou, plus précisément, comment Anna Kavan est devenue Anna Kavan :
« Anna Kavan n’est pas née Anna Kavan, elle l’est devenue. »
« ANNA KAVAN (nom propre, fictif, Anna Kavan) est un personnage de fiction qui apparaît pour la première fois dans le roman Let Me Alone, signé Hélène Ferguson. En 1939, l’écrivaine Hélène Ferguson devient ANNA KAVAN (nom propre, réel, Anna Kavan). Ce qui relie et fabrique ce lien, entre l’autrice et l’héroïne, c’est l’identité narrative. Celle que chacun élabore, en construisant son propre récit, en se racontant19. »
Posant d’emblée l’ambiguïté ontologique de son objet, ANNA KAVAN, nom fictif devenu réel, Catherine Lenoble inscrit son projet dans un paradigme performatif, autour du concept d’identité narrative, dont elle va elle-même largement jouer dans son récit, composé de quatre parties écrites tantôt à la première personne, tantôt à la seconde personne du singulier.
Le récit Anna K s’inscrit en effet dans un régime à la fois mémoriel et intime qui le rapproche d’une tendance littéraire actuellement en vogue : ce que Dominique Viart20 appelle la littérature de terrain (sans pour autant que son travail mentionne les œuvres numériques ni la question des données) typique d’un « nouvel âge de l’enquête » tel que le qualifie Laurent Demanze21. Dans Anna K, en effet, il s’agit tout autant de produire un récit biographique sur Anna Kavan que de documenter l’enquête et d’en mesurer les effets sur l’enquêtrice. La littérature contemporaine comprend de fameux exemples de cette double démarche, chez Ivan Jablonka ou Philippe Jaenada (prix Femina en 2017 pour La Serpe). Tout en se rapprochant de ce courant, la démarche de Catherine Lenoble est également imprégnée d’une méthodologie inspirée de la science des données, voire des humanités numériques littéraires, qui ont transformé le texte littéraire en données, pour proposer de nouvelles méthodes interprétatives : les travaux de Stéfan Sinclair et Goeffrey Rockwell22 en constituent un bon exemple. La captafiction naît de cette rencontre entre deux démarches, l’une littéraire, l’autre scientifique, qui ont à cœur de proposer des méthodes pour rendre le monde plus intelligible.
Comme elle s’en explique dès le début de l’ouvrage, Catherine Lenoble a découvert Anna Kavan lors d’un séjour en Slovaquie, après avoir déniché l’un de ses ouvrages chez un libraire. D’autres lectures suivront, en parallèle desquelles se développe peu à peu une passion pour tout ce qui la concerne. Commence alors une collecte d’informations analogiques (ouvrages, archives, correspondances), mais surtout numériques (bases de données, sites web, communautés de lecteurs rassemblés sur les forums ou les réseaux sociaux). Bientôt, la collecte tourne à l’obsession : comprendre l’œuvre, comprendre l’artiste, comprendre les données.
Anna Kavan est en effet une figure complexe. Ses pseudonymes (le vrai nom d’Anna Kavan est Helen Woods, qui se trouve être le même nom que sa mère, ses premières œuvres ont été publiées sous le nom d’Helen Ferguson, également le nom de son premier mari, puis elle a choisi Anna Kavan), son nomadisme (elle a énormément voyagé en Europe, en Asie et aux USA), sa vie amoureuse aussi trépidante que malheureuse, sa dépendance à l’héroïne qui causera sa perte en ont fait une figure romanesque prisée des biographes. Beaucoup s’y sont cassé les dents :
« [Je] découvre les archives de cet universitaire américain, Richard Centing, qui entreprit d’écrire une biographie d’ANNA, sans jamais y parvenir. […] Callard mentionne la “malédiction ANNA KAVAN”, qu’elle aurait eu de nombreux aspirants, prêts à relever l’énigmatique défi, en vain. Dans sa liste il cite Clive Jordan, un journaliste américain qui malgré les voyages, de Tulsa à Auckland, échoue. La biographie se transforme en article, intitulé “Among the lost things”, publié dans le Daily Telegraph en 1972. Vient ensuite Priscilla Dorr, doctorante à l’université de Tulsa au milieu des années 1980, lancée sur une thèse : “Anna Kavan: A Critical Introduction”. Avec la mort du second légataire, Raymond Marriot, la bibliothèque McFarlin récupère en 1992 une correspondance épaisse de plus de 800 lettres, le fameux gros morceau. Dans la foulée, Perter Own propose à Priscilla Dorr un travail biographique. Quand Callard se rend à Tulsa la même année, pour commencer la biographie de R., il rencontre Priscilla aux archives. Il rapporte dans sa lettre les difficultés éprouvées par la thésarde qui passe aux aveux un soir, après avoir bu quelques bières : l’univers d’Anna lui est trop obscur, elle renonce définitivement à la biographie23. »
Qui est Anna Kavan ? Le travail d’enquête s’annonçait déjà complexe dans le monde de l’archive analogique, Catherine Lenoble va lui ajouter un niveau de difficulté supplémentaire en plongeant dans l’univers du big data et de ses documents numériques :
« BOT(S)NIMENTS Choisissez un auteur mort et posez-vous la question de sa seconde vie, celle qui se poursuit et s’écrit sur le web, sur les plate-formes de blog et micro-blogging, sur les réseaux sociaux. […] Prenons l’exemple d’Anna Kavan. Anna qui ? Anna Kavan, une romancière britannique, née à Cannes en 1901 et décédée à Londres en 1968, dont l’œuvre, culte pour certains, reste néanmoins inconnue du grand public. Une énigmatique héroïnomane qui ouvre plusieurs robinets à la fois : flux autobiographique, flux de l’inconscient et flux onirique. Genre slipstream – fiction de l’étrange – bien avant que le terme soit inventé par Bruce Sterling en 1989. L’écrivain méconnu, au travail obscur, un bon cas d’étude. Penchons-nous sur le cas Kavan. Son oeuvre a-t-elle une deuxième chance d’être repêchée, repérée, éclairée ?
Lançons une requête. Environ 1 280 000 résultats 0,27 secondes.
Bienvenue dans l’ère du Big Data, le merveilleux volumineux monde des données, véritable levier de croissance pour ceux qui savent les collecter, les analyser, les croiser24. »
La proposition à la fois créative et théorique de Catherine Lenoble vient ainsi renouveler le genre biographique, mais également celui de l’enquête, en proposant une nouvelle stratégie de recherche, inspirée de la science des données. Là où les archives institutionnelles et les outils de documentation constituent la source par excellence du biographe et du chercheur traditionnel, que devient l’exercice d’écriture biographique lorsqu’il se déplace sur le web, et qu’il est assisté par ordinateur ? Peut-on résumer une vie, percer le secret d’une œuvre à l’aide de graphiques et de représentations statistiques ?
L’écriture littéraire des données : une poétique de la curation numérique
La démarche de Catherine Lenoble reste finalement celle d’une collectionneuse, comme la littérature et l’art en général en ont produit depuis longtemps. La captafiction ne fait que poursuivre et parfaire la tendance à l’effet de liste et au fragment que l’on connaît assez bien par ailleurs. Elle encourage l’écrivain à accumuler les matériaux d’écriture, pour mieux produire du sens à travers leur curation : penser, classer, pour reprendre l’expression de Perec. Mais là où de nombreuses collections d’écrivains demeuraient souvent anecdotiques, au sens où elles n’étaient pas portées à la connaissance du public, Catherine Lenoble va transformer son entreprise de collection en travail de publication. L’occasion de questionner l’influence des outils numériques de curation sur le travail de mémoire.
Ce geste de curation commence avec la réalisation de Kavan.land, un dataset consacré à Anna Kavan, accessible en ligne. Si l’on me permet cette analogie, Kavan.land constitue un exemple assez inédit de data paper littéraire et poétique :
« Kavan.land est une archive sémantique et fictionnelle développée à partir d’une collection de data autour de la romancière britannique Anna Kavan (1901–1968). […] Archive mineure élaborée sur plusieurs années, Kavan.land interroge, à l’ère du web-folklore et du Big Data, l’héritage et la valeur littéraire de l’œuvre de Kavan, présenté sous la forme de déclarations textuelles et interprétations visuelles (graphes, requêtes, prose sémantique, collection indexée de tags et d’URL25). »
Les données proviennent de sources électroniques existantes glanées sur la toile, organisées manuellement ou automatiquement, faisant ainsi émerger un territoire curieux, entre fiction et documents, web des données et littérature. Le travail éditorial de HYX donne à voir cette hétérogénéité du corpus déjà passé par la médiation des outils de recherche numériques, à commencer par Google, rebaptisé Papa par l’autrice.
Figure 2 : Anna K, page 37, capture d’écran (pleine page) reproduisant la première page des résultats d’une recherche Google « Anna Kavan ». Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.

Bien évidemment, Lenoble se montre critique vis-à-vis des grandes plateformes et des outils standardisés du web, dont elle note à plusieurs reprises l’influence structurante, y compris sur le travail de curation lui-même :
« Sous couvert de son panda diplomatique et de son libre pingouin, Papa fait le tri. Zen. Ying et Yang. Chapeaux blancs et chapeaux noirs. Le bien, le mal. Il en prend grand soin, en les nettoyant, cinq à six cents fois, par an. Ce qui n’est pas sans incidence – les algorithmes, le grand ménage de Papa – sur notre manière de voir, trier, accéder, consulter lire et au bout de la chaîne : transmettre26. »
« Au point d’écrire une nouvelle histoire, d’inventer de nouvelles publications, de confondre les individus : le portrait en mosaïque d’Anna Kavan sur Google image fait ainsi apparaître l’actrice Helen Woods (confondue par la « maladroite ré-écriture algorithmique » avec un autre nom d’Anna Kavan : Helen Wood)27. »
Ainsi l’outil numérique apparaît-il à son tour comme un générateur d’identité narrative, en ce qu’il participe à l’éditorialisation de l’entité Anna K, à titre posthume, ajoutant des données aux données, modifiant leur indexation, influençant les algorithmes de classement. Cette dimension performative de l’acte de curation apparaît par ailleurs dès les premières pages de l’enquête, avec cette commande quasi démiurgique reproduite en toutes lettres, geste de création du dossier ANNA K où l’archive prendra forme :
« cd ~documents/WRITE/ANNA K.28 »
Avec son ambition exhaustive, sa masse prolifique d’informations, Kavan.land offrirait-il la matière pour nous permettre de percer le mystère Anna Kavan ? Une partie du travail de Lenoble semble y parvenir. Force est de constater ici que l’exercice fonctionne très bien tant que l’ambition graphique demeure limitée : avec des formes de visualisation plutôt basiques (nuages, dispersion plots), le dataset ANNA K se laisse plutôt simplement lire et analyser.
Figure 3 : Dispersion Plot
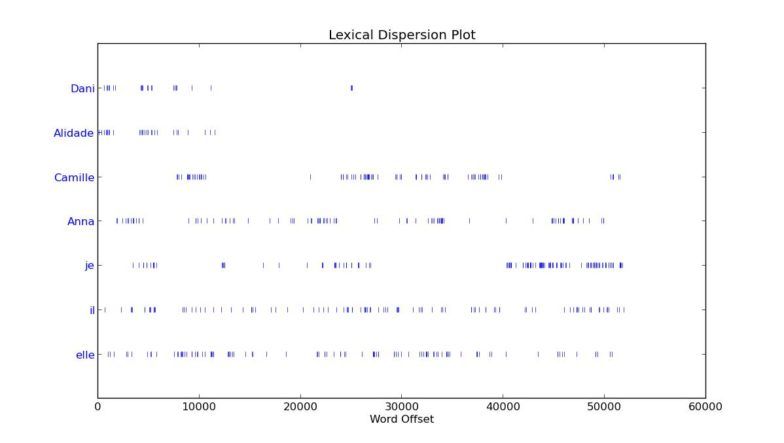
Figure 4 : Graphes
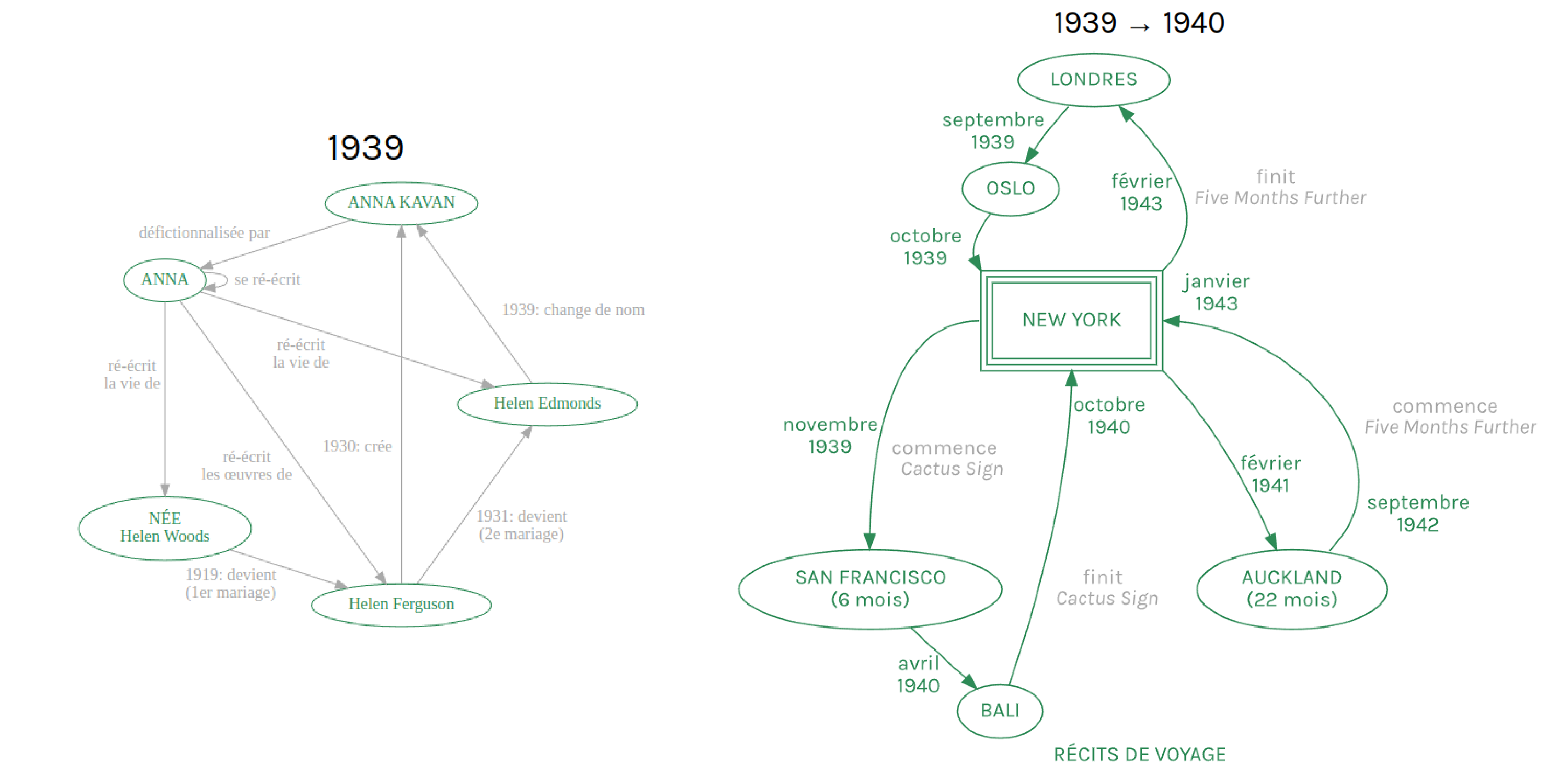
Figures 3 & 4 : Visualisations analysant les données recueillies par Catherine Lenoble sur Anna Kavan, reproduit sur l’archive numérique kavan.land. Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.
Mais les choses se compliquent assez vite. Obnubilée par la recherche de patterns, l’autrice réalise un important travail de modélisation, plutôt convaincant il faut l’avouer, mais qui demande au lecteur une attention déjà plus soutenue. Le récit se délinéarise en effet pour présenter une série de formules, qui requiert à la fois une connaissance succincte des travaux des formalistes russes (pour bien saisir la référence à Vladimir Propp et ses travaux en analyse structurale), ainsi qu’une certaine littératie numérique loin d’être partagée par l’usager lambda (afin de maîtriser, par exemple, le concept de variable) :
« À la manière de ce vieux fou de Vladimir Propp […], tu te mets en tête d’étudier la morphologie des œuvres d’ANNA. Tu cherches et tu trouves tes propres formules. En lisant, annotant, parfois même murmurant, tu repères des variables et des constantes. Tu détectes deux modèles29. »
Figure 5 : Anna K, p. 32. Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.

« Le premier met en avant un protagoniste avec un prénom et un nom de famille ; il ou elle vit dans un environnement sous contrainte. […] L’émancipation chez ANNA se joue soit, dans la disparition d’un facteur ou d’une variable (+), soit dans la rencontre avec un jeune homme (h1, h2)30. »
S’ensuit une série de formules modélisant chacune des publications d’Anna Kavan, selon un système d’encodage établi et défini plus tôt par Catherine Lenoble.
Figure 6 : Anna K, p. 34. Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.

Le tour de force de l’autrice est alors de proposer au lecteur une mise en données d’un corpus littéraire dont elle donne à voir et à lire le fonctionnement, mais également les potentialités interprétatives. Le lecteur est ainsi poussé à développer une nouvelle compétence de lecture délinéarisée, inspirée de l’algorithmique, où se dessine moins un récit actualisé que l’ensemble de ses potentialités. Cette lecture fait écho à l’herméneutique modélisante, définie par Johanna Drucker, mais également à l’herméneutique des données que Bachimont et Vaerlet appellent de leurs vœux.
C’est ainsi que Lenoble construit une poétique de la curation. Comme le sous-entend le concept d’éditorialisation, mais comme l’a défendu également Kenneth Goldmith31, tout travail de création passe désormais non plus par la recherche de l’inédit, mais par un travail de curation et d’association des données. Le travail de curation s’apparente ainsi à une démarche qualitative qui cherche à répondre à l’enjeu quantitatif des données.
Anna K : folle à lier ?
En un sens, cette poétique de la curation s’apparente à un art de créer du lien, comme en témoignent d’ailleurs les nombreux graphes produits par Lenoble et le collectif Open Source Publishing. Mais en se projetant ainsi dans la position de l’enquêteur chargé de faire émerger des relations, et donc du sens, l’écrivain de captafiction ne prend-il pas quelques risques ? Posons la question plus franchement : les données font-elles toujours sens, ou n’y projette-t-on pas ce que l’on veut y voir ?
Ultime chapitre de l’ouvrage, la partie « data mining » clôt l’enquête initiée par Catherine Lenoble de manière assez inattendue, dans un revirement où l’autrice semble éprouver les limites de l’exercice de visualisation de données – tant du point de vue conceptuel que technique, mais également herméneutique. Dans ce chapitre qui transporte l’enquêtrice dans les méandres de son archive, mais également dans un asile psychiatrique, l’écriture littéraire des données apparaît comme un exercice à haut risque :
« Tu tournes en boucle autour des mêmes événements, des mêmes fragments, des mêmes refrains, des mêmes revenants.
Ce qui t’intéresse chez ANNA K : le pattern familial et marital, le lit et la chambre, l’entrée et la sortie de la clinique, les voitures et son passeport, la période entre 39 et 35 […]. Et préciser, qu’entre temps, tu viens d’être admise au service des addictions comportementales32. »
L’exercice biographique glisse vers une narration intime, à la seconde personne du singulier, dans lequel la narratrice et ANNA K ont plus ou moins fini par ne faire qu’une.
Ce dernier chapitre comprend également de nombreuses propositions graphiques, ou du moins un jeu avec des formes de la visualisation graphique, cependant totalement décorrélée des données.
Car il ne s’agit plus ici de proposer une visualisation à partir des données préexistantes, mais à créer de nouvelles formes, tout en jouant sur les codes de la visualisation ou de modélisation UML, dont les principes sont détournés pour générer une interprétation plus figurative, de sorte que les dessins formés se laissent interpréter de plusieurs façons possibles : superposition entre une forme statistique ou modélisante, et une forme figurative.
Figure 7 : Anna K, p. 128. Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.

Dans le cas ci-dessus, par exemple, les éléments graphiques de relation (les flèches, pour le dire simplement) figurent les rideaux derrière lesquels la narratrice est cachée, mais va également symboliser l’enfermement dans la folie.
Figure 8 : Anna K, p. 130. Reproduit avec l’aimable autorisation de Catherine Lenoble et des éditions HYX.

Dans ce nouvel exemple, c’est un simple graphique en bâtons, avec un design 3D, qui devient soudainement un dessin de lit.
L’ambiguïté graphique avec laquelle joue Catherine Lenoble rappelle finalement le concept d’interprétation modélisante de Johanna Drucker, selon laquelle notre « compréhension des formes de connaissance n’est qu’une connaissance des formes33 ». Ainsi,
« L’interprétation modélisante appelle aussi des formes graphiques différentes, distinctes, capables d’exprimer l’ambiguïté, la contradiction, la nuance, le changement et d’autres aspects de considération critique34. »
En s’extrayant de la visualisation des données pour créer un dessin plutôt figuratif, qui va lui-même ouvrir à une interprétation symbolique, Catherine Lenoble ouvre alors la voie à une « compréhension non représentationnelle de la visualisation », même si ces derniers graphs n’ont pas été générés avec des données. Car il ne s’agit plus tant de produire ici une image des données qu’une image de leur visualisation.
Dans une métaphore finale associant le data mining à la trépanation crânienne, Catherine Lenoble laisse son lecteur avec une sensation ambivalente, comme si toutes ces données, malgré l’impression ou le fantasme d’exhaustivité et de rationalisation qu’elles supposent, ne pouvaient empêcher Anna K de nous échapper finalement :
« ANNA se tourne et se retourne dans son lit, marmonnant : “les rats… les voilà à ma porte”. Recroquevillée du côté de la table de chevet, elle lorgne sur la lettre dans laquelle le président du Comité lui fait savoir tout personnellement que “les doigts de la propriété intellectuelle et artistique nous ont permis d’analyser votre œuvre, grâce à la mémoire du fair use, invoquée avec finesse et maîtrise, et ce malgré les difficultés de la tâche, au regard du sujet et de l’ampleur de la variété des secteurs d’activité. Comme nous l’avons relevé précédemment, le détournement d’outils informatiques et d’algorithmes ayant conduit à l’utilisation de terminologies variables, il convient de sauver les apparences, par un acte d’extraction provisoire, entièrement effectué dans le crâne.”35 »
« Tandis que tous s’auto-congratulent pour le partage des miettes numériques, leur attention converge vers une horloge, au gong dépressif, qui semble négocier avec sa propre maladie. À y regarder de plus près, l’horloge indique la mort d’ANNA K. Une énième fois36. »
Conclusion
Dans Anna K, Catherine Lenoble questionne la capacité du monde à rester interrogeable après sa mise en données dans l’espace numérique. Et tandis que Françoise Lavocat, dans ses travaux sur la distinction entre factuel et fictif cités en introduction, signalait la nécessité cognitive de conserver un régime de fiction, Lenoble pointe le grand défi cognitif de notre époque, incarné par le big data, un ensemble de données si vaste qu’il dépasse justement les capacités du cerveau humain – y compris sa capacité à faire fiction ? En réponse à ce défi, elle invente une nouvelle forme d’écriture, ce que j’ai proposé d’appeler la captafiction, qui combine deux régimes d’écriture aux méthodes sans doute assez voisines : la science des données d’une part, l’écriture de l’enquête d’autre part. Avec la première, Catherine Lenoble prend, comme on l’a vu, des libertés poétiques et (auto)fictionnelles, qui mettent à mal le faux certificat d’authenticité de la donnée ainsi que la fonction objectivante de ses visualisations, parvenant ainsi à proposer à ses lecteurs un parcours herméneutique exigeant, mais efficace. À la seconde, Catherine Lenoble apporte de nouvelles méthodologies, fondées sur des outils numériques qui, comme elle le démontre, se sont imposés comme de nouvelles technologies de l’intellect. Sans doute n’avons-nous pas encore terminé l’inventaire des mutations conceptuelles posées par ces nouveaux médias de la connaissance. En attendant, la captafiction apparaît comme une piste prometteuse pour participer à la reconstruction d’un régime du sens en contexte numérique.