
Les pratiques de l’édition savante1 sont les héritières d’une méthodologie qui remonte aux premières tentatives de reconstitution d’un texte original ou du moins d’une version canonique pour des textes aux traditions complexes comme la Bible, les œuvres d’Homère, Cicéron, Virgile, Chrétien de Troyes ou encore Shakespeare2. Depuis les humanistes du xvie siècle jusqu’à nos jours, les éditeurs ont mis au point différentes méthodes pour rendre la pluralité textuelle. Ces méthodes vont de la restitution minutieuse d’un texte le plus proche possible de sa source – restitution de la mise en page, des abréviations, etc. – à la reconstitution d’un archétype le plus proche possible de la version de l’auteur. L’éditeur y retrace les relations entre les différentes réalisations du texte depuis le(s) texte(s) de l’auteur jusqu’aux réalisations accessibles aujourd’hui3.
Depuis près d’un siècle persiste une tension méthodologique entre éditions « conservatrices », qui suivent un témoin issu de la tradition manuscrite, et les éditions « reconstructionnistes », qui cherchent à retrouver le texte original de l’auteur. La méthode reconstructionniste, née, entre autres, des travaux de K. Lachmann4, s’est établie comme la méthodologie de référence dans les études classiques. Ces éditions opèrent une nette distinction entre le texte conçu comme étant le texte original et les sources manuscrites regardées comme un véhicule imparfait du texte à reconstruire, là où l’éditeur d’une édition conservatrice envisagera le texte du témoin manuscrit comme une réalisation possible du texte5. La méthode conservatrice, initiée au début du xxe siècle par J. Bédier, prône l’édition du « meilleur des manuscrits » (qualité du texte, place dans la tradition manuscrite). Elle se prête tout particulièrement à l’édition des textes médiévaux, en permettant de conserver les graphies d’un document qui a réellement circulé, là où la méthode reconstructionniste aboutit à la création d’un texte dont la langue ou les graphies ne sont plus en lien avec des attestations historiques6. Dans la continuité de cette approche, dans les années quatre-vingt, B. Cerquiglini défend, dans l’Éloge de la variante7, la place du témoin manuscrit comme représentant d’un état de transmission du texte ayant sa valeur intrinsèque. Il donne alors naissance à la New Philology et influence également la philologie génétique8. Dans la continuité de ces réflexions, Peter Shillingsburg définit son travail davantage comme la présentation d’un processus textuel, plutôt que comme l’établissement d’un produit final immuable9. Enfin, J. Bryant considère que « the only “definitive text” is a multiplicity of texts, or rather, the fluid text »10, proposant ainsi un point de vue sur le texte opposé à celui de l’école lachmanienne. S’ajoutent, aujourd’hui, au paysage scientifique, les éditions génétiques qui retracent le processus complet d’écriture de l’auteur à travers l’analyse de ses brouillons11. Toutefois, si les méthodes changent, les éditions scientifiques visent toutes l’établissement d’un texte fiable et contextualisé, quelle que soit l’alternative choisie.
Enfin, malgré le soin apporté à ces éditions, elles sont souvent difficiles à appréhender à cause des contraintes imposées par le format papier qui entraînent l’utilisation de règles de représentation et/ou de schématisation de l’information12, en raison du nombre restreint d’informations transmissibles aux lecteurs. En outre, jamais un livre ne pourra contenir dans ces pages les illustrations, l’arrangement des feuillets, les variations de la tradition manuscrite et rester consultable13. Enfin, ces productions, figées dans le papier, nécessitent d’être mises à jour, voire refaites au gré des évolutions méthodologiques ou des nouvelles avancées de la recherche. Les éditions numériques ont, pour partie, émergé pour essayer de dépasser ces limitations, permettant de consulter les numérisations des sources, d’offrir des parcours de lecture, de plonger le lecteur dans un réseau de multi-fenêtrages14 et d’hyperliens pour proposer une lecture augmentée. Ainsi, après avoir dressé un état de l’art de l’édition numérique, nous présenterons ses standards, son lectorat, mais également ses nouveaux enjeux. Enfin, nous analyserons l’impact des récentes innovations technologiques sur les systèmes de production textuelle.
Édition numérique : définition et héritages méthodologiques
Le passage des éditions au format numérique n’est pas synonyme d’une révolution totale des méthodologies de l’édition15. Au contraire, elles semblent être solidement enracinées dans les débats philologiques du xxe siècle et ont contribué à enrichir les multiples voies envisageables. Certains théoriciens de l’édition numérique considèrent le passage au numérique comme une évolution naturelle de la philologie traditionnelle. Selon H. W. Gabler, elles doivent respecter les mêmes critères d’érudition scientifique pour l’établissement du texte et être mises en œuvre à l’aide d’instruments qui renforcent l’analyse critique du texte (collation, concordance, stemma, etc.)16. En outre, la philologie matérialiste tire parti de la mise en ligne des numérisations des documents, de systèmes de multifenêtrage pour la comparaison, et de la contextualisation diachronique et synchronique des œuvres via des systèmes d’hyperliens17.
Édition numérique scientifique : définition
Que signifie éditer numériquement ? Patrick Sahle propose ces quelques critères pour définir les « digital scholarly editions » (DSE) que nous reprenons et traduisons pour partie ci-dessous18 :
-
S pour Scholarly : une édition doit offrir une critique textuelle, apportant ainsi une valeur supplémentaire par rapport à la simple mise en ligne d’un fac-similé. Une bibliothèque numérique, qui se contente de numériser des documents, sans offrir une analyse critique, ne répond pas à cette définition.
-
D pour Digital : une édition numérique ne doit pas pouvoir être convertie en une édition imprimée sans une perte substantielle d’informations ou de fonctionnalités. De même, une conversion numérique d’une édition imprimée n’est pas une édition numérique, sauf si elle est enrichie de contenus ou de nouvelles fonctionnalités.
-
E pour Édition : une édition numérique doit fournir un texte, qu’il s’agisse d’une simple transcription ou d’un texte plus élaboré. Ainsi, les catalogues, index ou bases de données ne sont pas inclus dans cette catégorie.
Enfin, selon J. Carlquist, une édition scientifique numérique de qualité doit s’appuyer sur un encodage complexe et riche, doit inclure un texte interrogeable et des images, et être enrichie de métadonnées appropriées et riches de sens, un apparat critique, des index et un glossaire19.
Édition documentaire contre édition monumentale ?
Les nouvelles possibilités offertes par les éditions numériques ont ravivé le débat entre éditions documentaires et éditions monumentales, pour reprendre les termes de P. Robinson :
One cannot know the work without the documents – equally, one cannot understand the documents without a comprehension of the work they instance. From this, a principle appears: a scholarly edition must, so far as it can, illuminate both aspects of the text, both text-as-work and text-as-document. Traditional print editions have focused more on the first. An evident advantage of digital editions is that they might redress this balance, by including much richer materials for the study of text-as-document than can be achieved in the print medium. 20
L’objet numérique libéré des contraintes du papier permet une accumulation d’images, de textes et de représentations offrant la possibilité inédite de représenter le texte dans ses réalisations en tant que document, là où le papier représente le texte comme monument. Bien que nombre d’éditions en ligne soient tournées vers le texte comme document, comme les éditions du projet ELEC de l’École nationale des chartes21, de nombreux critiques ont souligné les failles d’une pratique qui se limiterait uniquement à une représentation imitative de la source. Toutefois, M. Dahlström clame combien il est fallacieux de dire qu’une édition numérique imitative ne découle pas d’une démarche scientifique22. La conversion des signes manuscrits en caractères informatiques relève déjà d’une interprétation, car le passage à une représentation normalisée entraîne une réduction de la variété des formes de lettres de la source23. Transcrire et encoder sont le fruit d’un processus de sélection impliquant réflexion et méthode : choix de la granularité de l’imitation de la source, représentation du système abréviatif, niveaux de différenciation des allographes, etc. Toutefois, quoiqu’on puisse considérer qu’une édition documentaire est déjà le premier pas vers une édition critique en tant que source primaire24, il est primordial de dépasser le stade de la mise en ligne d’archives ou d’une accumulation documentaire, sans quoi le risque est de perdre le lecteur dans un amas d’informations dont il ne parviendra pas à faire sens, amenant à une forme de refus d’éditer25.
Certains projets comme le projet Hyperdonat ont expérimenté une voie médiane, essayant de concilier l’approche du texte-comme-document et du texte-comme-monument en proposant un texte de référence et la possibilité de parcourir la tradition manuscrite à travers une interface de comparaison des témoins26. Le projet d’édition de Guiron le Courtois, en s’appuyant sur la modularité des corpus numériques, propose d’établir le texte branche par branche avec des éditions intermédiaires pour chacune d’entre elles, afin d’établir un texte critique qui garde une trace de la surface linguistique pour chaque branche de la tradition. La réunion des différentes éditions permettra à terme d’arriver à l’édition critique finale de l’œuvre, tout en suivant les innovations du texte au fil de la transmission27.
Ainsi, même si les premières éditions numériques ont surtout favorisé le texte comme document, tandis que les éditions papier ont favorisé le texte comme monument, les progrès techniques de ces dernières années, grâce, entre autres, à la reconnaissance automatique d’écriture (ATR), offrent la possibilité de traiter des corpus de plus en plus vastes, et donc de traiter des traditions manuscrites complètes, tout en établissant un texte de référence.
Les différentes formes d’édition numérique
L’une des premières applications du numérique pour la mise en ligne de textes a été la création de bibliothèques numériques, offrant la possibilité de mener des fouilles textuelles. En France, l’Observatoire de la vie littéraire (OBVIL, 2014-…)28 a mis à disposition plus d’une trentaine de corpus littéraires français structurés en XML TEI29 sur Github30, accompagnés d’outils tels que Dramagraph pour faciliter l’analyse de la répartition des répliques dans les pièces de théâtre31. À l’échelle internationale, le projet Perseus Digital Library (1987 – …)32 donne accès à des centaines d’éditions de textes, ainsi qu’à une interface de consultation, de recherche, et à des URN33 pérennes pour citer les textes, tout en assurant l’accès aux fichiers sources encodés en XML TEI.
Certaines éditions numériques, tout en respectant les codes de l’édition traditionnelle, proposent des éditions enrichies. C’est le cas du projet la Queste del saint Graal (1999 – …) de Christiane Marchello-Nizia et Alexei Lavrentiev34 à l’origine de la création du portail de la Base de français médiéval (BFM)35 qui héberge des éditions en XML TEI de textes en ancien français. Grâce au média numérique, la Queste met en regard le texte avec sa source, tout en fournissant une transcription imitative avec les abréviations et une transcription normalisée. En outre, le texte est intégralement étiqueté : lemmes et POS (Part-of-Speech36) facilitant les recherches lexicales et des analyses textométriques.
Influencés par la New Philology, certains projets proposent des parcours de lecture où la matérialité des œuvres est centrale. Le projet The Walt Whitman Archive (1995– …)37 ou encore The Rossetti Archive (1993-2008)38 en sont des exemples. Le projet The Complete Writings and Pictures of Dante Gabriel Rossetti offre un parcours enrichi de numérisations d’un corpus où l’auteur a non seulement écrit les textes, émis des productions picturales (souvent en amont du texte et en lien étroit avec lui)39, mais aussi élaboré la conception matérielle des livres, leur donnant une importance cruciale à la compréhension du processus créatif de l’auteur40. Plus récemment, le projet Woolf Online retrace l’univers mental de Virginia Woolf en mettant à disposition des lecteurs ses brouillons et des collections d’images. Pour les éditions génétiques, le numérique permet d’explorer les brouillons d’auteurs. Dans l’édition de Frankenstein de Mary Shelley du projet the ShelleyGodwin Archive (2013– …)41, on peut parcourir les différentes étapes de l’écriture et identifier les mains responsables des corrections manuscrites42. En France, le projet Bovary (20022009)43 propose un plan de la création de l’œuvre de Gustave Flaubert, permettant de retracer le processus d’écriture du roman. Ces projets, à travers la création de réseaux d’hyperliens et une documentation abondante, mettent en scène de manière dynamique le processus créatif. Elles promeuvent une textualité numérique ouverte et interactive en opposition au livre statique et fermé44. Toutefois, une telle abondance de documents demande un investissement important du lecteur, avec une navigation complexe pouvant entraîner une perte du sens au profit d’une navigation compulsive, comme le décrit A. Mangen :
The urge to click can easily become too tempting to resist, if we are cognitively or perceptually stimulated with possibilities that seem more exciting than what we are presently focused on. Knowledge sites have a wealth of potentials that can risk disrupting our phenomenological preoccupation with them, thereby limiting the possibility of hermeneutical reflection. 45
En outre, les systèmes de renvoi dépendent des interfaces en ligne, ce qui les rend vulnérables aux mises à jour techniques, menaçant ainsi leur maintenabilité.
Le passage au format numérique offre donc des opportunités inédites aux éditeurs et permet d’aborder des corpus de manière exhaustive, tout en engageant le lecteur dans des expériences interactives. Toutefois, la vigilance reste de mise pour éviter la prolifération d’informations sans valeur critique et assurer la pérennité des projets dans un environnement numérique en constante évolution.
Édition numérique : comment, pour qui, nouveaux enjeux ?
Les éditions numériques découlent d’une histoire décennale ayant forgé une communauté scientifique unie autour de la norme qu’est la TEI (Text Encoding Initiative). Non seulement elle a fourni les outils nécessaires à la création d’éditions numériques, mais elle a également été propice à la réflexion et aux échanges sur les questions relatives à l’édition des textes au sein d’une communauté dynamique et ouverte.
Un standard : XML TEI
La TEI a vu le jour en 1987 avec pour objectif de standardiser la représentation informatique des données textuelles et des sources historiques. La même année, lors d’une réunion réunissant des spécialistes des archives, des sciences computationnelles et des sciences des textes à Poughkeepsie (États-Unis), la TEI s’est dotée de guidelines46. Depuis 2003, elle repose exclusivement sur le langage XML (eXtensible Markup Language), qui fonctionne sur un système d’arborescence et d’imbrication strict. Son système de balisage permet d’enrichir le texte source d’informations aussi diverses que la hiérarchisation du texte, les entités nommées et les annotations linguistiques et plus encore, le tout dans un langage lisible à la fois par l’humain et par l’ordinateur. L’objectif de la TEI est de fournir une solution aussi bien aux débutants pour structurer un texte qu’aux experts cherchant une solution pour bâtir un corpus complexe. Elle offre suffisamment de liberté pour permettre à chacun de proposer un encodage adapté à sa source et à ses objectifs de recherche. L’esprit même de la TEI n’est pas de contraindre les éditeurs à un choix technique appliqué de manière mécanique, mais de permettre aux choix épistémologiques de rester centraux dans la modélisation des données. Cependant, la contrepartie de cette liberté se traduit par des pratiques éditoriales, tout comme la philologie traditionnelle, qui ne sont pas uniformisées.
Enfin, bien que la plupart des projets cités dans cet article reposent sur des corpus encodés en XML TEI, il est indéniable que le standard n’est pas encore appliqué de manière systématique. Comme le soulignent G. Franzini, S. Mahony et M. Terras, seulement 37 % des éditions numériques parmi celles répertoriées dans un catalogue de 187 éditions suivent les prescriptions de la TEI47.
Figure 1 : Répartition des technologies utilisées pour les éditions numériques, illustration issue de G. Franzini, S. Mahony et M. Terras, « A Catalogue of Digital Editions », 2016
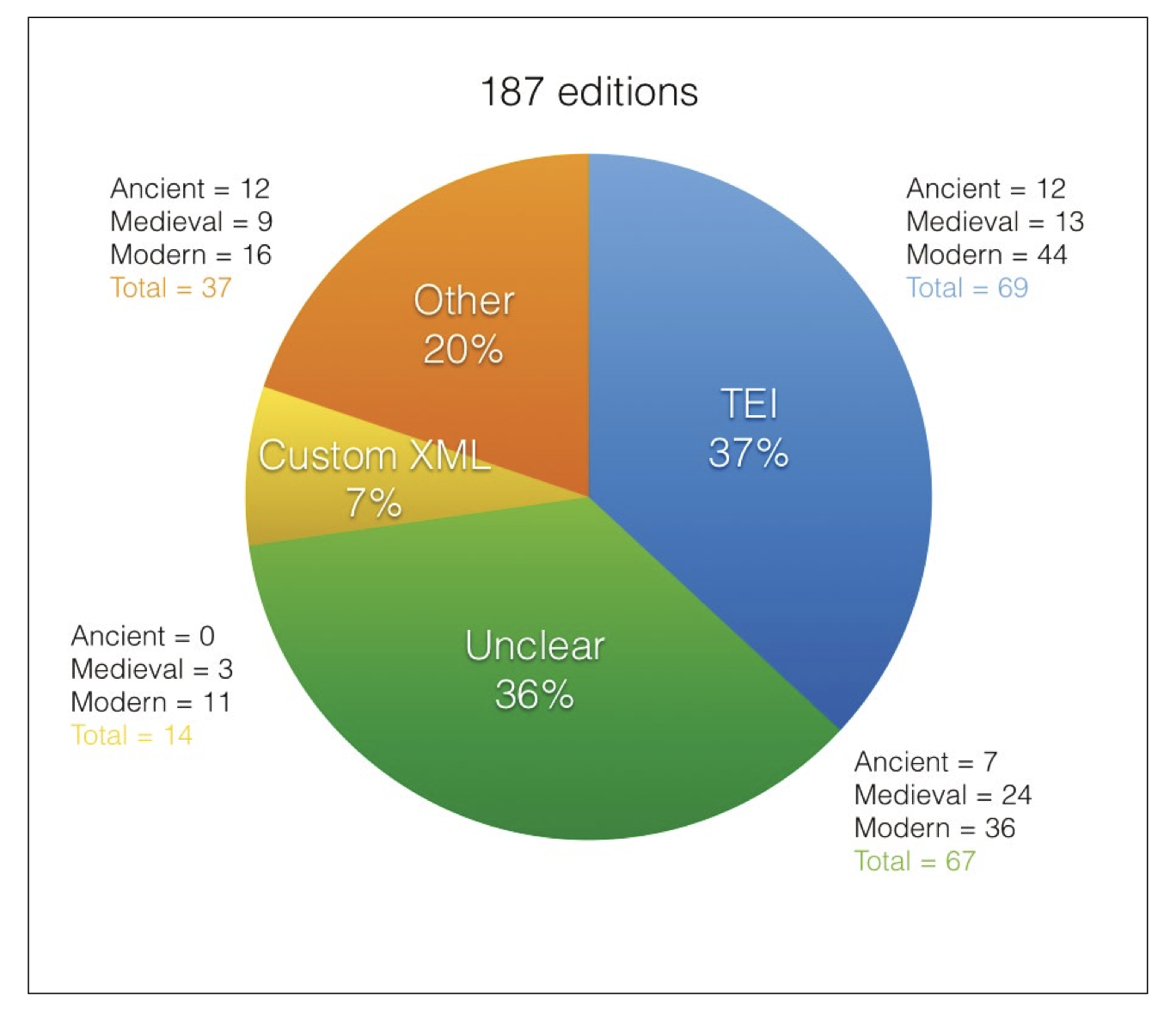
Ainsi, malgré l’établissement de standards documentés et partagés par une large communauté, les pratiques de l’édition numérique ne sont pas encore unifiées, ne serait-ce que d’un point de vue technologique.
Qui sont les « lecteurs » des éditions numériques ?
Il est relativement complexe de prévoir quels seront les usages et les lecteurs des éditions numériques. Non seulement le lectorat potentiel échappe à toute délimitation disciplinaire, mais la multiplicité de ses usages ouvre encore davantage les possibilités, entraînant même parfois une perte de contrôle de l’éditeur sur l’utilisation de son édition48. Bien que l’on qualifie souvent les « utilisateurs » d’éditions numériques sous le terme générique de « lecteurs », le terme même est contestable dans le cas d’une analyse textuelle basée sur du distant reading49. Voici une tentative de délimitation de trois types principaux d’utilisateurs/lecteurs en fonction du type d’usage du texte50 :
-
Le lecteur-consultant qualitatif, qui adopte une lecture linéaire du corpus similaire au support papier, soit pour lire une œuvre accessible en ligne, soit pour établir un corpus à analyser de manière qualitative.
-
Le lecteur-explorateur pour les éditions basées sur du multifenêtrage ou des hyperliens, comme les projets The Rossetti Archive ou encore Woolf Online. Le lecteur y crée son propre parcours dont la complexité peut être déterminée en fonction de son degré d’expertise.
-
Le lecteur-utilisateur de données. Ce sont des utilisateurs qui ne consultent pas les interfaces de lecture ou d’exploration, mais qui utilisent le texte brut, structuré, voire enrichi pour faciliter la fouille51 via une API ou en récupérant directement les fichiers sources pour des études quantitatives ou en faire des données d’entraînement52. Le texte est alors traité comme des données53.
L’éventail des utilisations possibles est très large, de la simple consultation à la fouille de texte, exigeant une donnée structurée et enrichie. Le traitement du texte comme donnée implique un passage d’une pratique individuelle visant à produire un objet fini à la production de données réexploitables dans un autre cadre que celui pour lequel elles ont été créées. Ainsi, l’éditeur numérique n’est plus simplement le producteur d’un texte clos sur lui-même, mais il devient également un modélisateur de données à partager, d’où l’importance de l’utilisation de standards (caractères Unicode, encodage, etc.) pour en faciliter la réutilisation.
Nouvelles problématiques
Les éditions numériques demeurent aujourd’hui un ensemble de pratiques multiples, ce qui les rend difficiles à évaluer. En effet, tandis que « les éditions critiques au format imprimé répondent, pour leur part, à des modèles d’évaluation et de validation instaurés dès le xixe siècle […]. Les éditions critiques numériques sont pour le moment peu nombreuses à faire l’objet de telles recensions »54. Les méthodes classiques d’évaluation ne s’appliquent pas et les éditeurs scientifiques se heurtent à une difficulté de reconnaissance de leur travail55. En France, des groupes de travail pour la mise en place de standards émergent, tels que l’ancien consortium Cahier56, ou encore le consortium ARIANE-HN57. À l’international, on peut citer les Guidelines for Editors of Scholarly Editions58 de la Modern Language Association qui proposent une grille pour guider les éditeurs sur les informations importantes à fournir sur le corpus et son établissement, ainsi que sur sa mise en ligne et la question de la préservation des données59.
Comme le soulignait Frédéric Duval, la force du numérique réside dans sa modularité : « une édition numérique peut proposer des parcours plus ou moins ouverts, de la consultation libre d’un dépôt d’archives à des parcours commandés par des approches et intérêts divers60 ». Cette modularité s’étend également au fait que l’œuvre peut être modifiée à l’infini61. Ces éditions pourront être maintenues au cours du temps par une succession d’experts62. Cependant, cette modularité engendre de nouvelles problématiques. Alors que les éditions scientifiques papier produisent un nouvel objet en guise de mise à jour, l’édition numérique est modifiée, allant parfois jusqu’à remplacer la version précédente, soulevant dès lors la question du versioning. Cette problématique a déjà été abordée par la TEI, qui permet la création d’un journal des versions dans l’élément <versioningDesc>, énumérant les dates et les responsabilités des changements, sans toutefois permettre de remonter à une version antérieure. Pour remédier à ce problème, E. Pierrazzo plaide en faveur d’une gestion du versioning au sein des logiciels d’édition numérique, assurant ainsi l’accès aux versions antérieures63. Cette gestion du versioning peut également être réalisée par l’archivage des fichiers sources.
Enfin, si les éditions numériques n’entraînent pas de frais d’impression, les coûts d’hébergement sur un serveur et de maintenance ne doivent pas être sous-estimés. L’utilisation de systèmes informatiques rend ces objets vulnérables à l’obsolescence. Là où un manuscrit se conserve des centaines d’années, la conservation des objets numériques est plus complexe et son obsolescence liée à différents facteurs, tels que l’obsolescence « fonctionnelle » (fichiers endommagés), l’obsolescence de l’entité qui assurait la mise en ligne, ou encore l’obsolescence technologique. Face à ce constat, il nous semble essentiel d’assurer, avant tout, la pérennité des données de l’édition dans des fichiers au format le plus simple et standard possible, comme le XML TEI, dans des dépôts pérennes, et de leur associer des DOI pour faciliter leur accès et leur citabilité (Nakala64, Zenodo, etc.).
Ainsi, l’édition numérique est encore en construction et cherche les critères de sa scientificité. La nouvelle économie dans laquelle elle s’inscrit n’est plus uniquement une économie du texte, mais une économie des données qui demande d’anticiper leur curation et la maîtrise des principes FAIR (Findable, Accessible, Interoperable, Reusable)65.
Vers un changement d’échelle
Avec la montée en puissance de l’intelligence artificielle et l’automatisation des chaînes d’acquisition textuelle, une transformation significative se dessine en termes de taille des corpus. Alors que l’édition se limitait autrefois à une œuvre ou à une section cohérente d’un ensemble plus vaste, l’idée d’éditer des œuvres sérielles ou complètes gagne du terrain. Même la très établie TEI s’est adaptée et cherche à fournir un encodage de base comprenant des informations essentielles pour les corpus destinés à une lecture à distance66. Cette capacité à accumuler des données textuelles pourrait faciliter la conciliation entre des approches du texte en tant que document et du texte en tant que monument, en permettant d’acquérir plus de texte plus vite et en facilitant, par exemple, une comparaison automatisée des témoins manuscrits, notamment par le biais d’une constitution semi-automatique du stemma. Cependant, cette nouvelle approche du texte comme données risque d’accentuer le fossé entre les philologues traditionnels et les humanistes numériques :
As I have argued elsewhere, it is difficult to treat texts responsibly as “data” when much of our data set is inaccurate, whether because of faulty editing or because of the lack of digitization of certain types of texts, particularly those by what we might think of as non-canonical authors. The tensions between such approaches threaten to create splits between digital editing and digital humanities reminiscent of the textual studies wars of the second half of the twentieth century.67
C’est pourquoi il est important que les spécialistes du texte s’investissent dans ces problématiques afin de contribuer à l’élaboration d’outils numériques (modèles de reconnaissance automatique d’écriture, reconnaissance d’entités nommées, assistance à la collation, alignement de traduction, annotations linguistiques, etc.). L’objectif est de guider la communauté scientifique, qu’elle soit traditionnelle ou spécialisée dans les humanités numériques, pour rendre accessibles un nombre accru de textes, peut-être moins canoniques, tout en respectant les normes scientifiques établies par la communauté, sans laisser des géants commerciaux s’emparer d’une forme de numérisation plus rentable que scientifique des fonds patrimoniaux68.
Acquisition automatique de texte
Grâce à des outils comme Transkribus69 et eScriptorium70, l’acquisition automatique de texte (ATR) permet de travailler sur des documents historiques complexes. Avec des corpus d’entraînement de qualité, les modèles de reconnaissance d’écriture manuscrite (HTR – Handwritten Text Recognition) peuvent atteindre des taux de précision de 92 % à 98 %, voire 99 %, faisant de l’acquisition automatique de texte une tâche résolue du point de vue informatique71. Actuellement, l’enjeu principal réside dans la production de données d’entraînement de qualité pour développer des modèles répondant aux critères scientifiques du monde de la recherche.
Pour maximiser la qualité des transcriptions, il est impératif d’utiliser des données d’entraînement de première qualité, en établissant des normes de transcription. Ces normes incluent la distinction ou non des allographes, le traitement des abréviations et la préservation des ligatures, mais aussi le choix d’un set de caractères de préférences unicode pour représenter les sources, choix qui doivent être dictés par des critères scientifiques, la nature des sources et les objectifs scientifiques72. Le consortium pour la reconnaissance d’écriture manuscrite des matériaux anciens (CREMMA) a élaboré des réflexions approfondies sur la manière de transcrire les vérités de terrain73. Deux documents ont émergé de ces efforts : un guide dédié aux documents médiévaux74 et un ensemble de recommandations pour les documents modernes75.
D’importants jeux de données ont également été produits grâce à la collaboration entre différents projets tels que CREMMA, FoNDUE (FOrmes Numérisées et Détection Unifiée des Écritures)76, Gallic(orpor)a77, HTRomance78 et HTRogène79. Ces corpus, englobant une diversité de sources du Moyen Âge aux imprimés du xxe siècle, respectent les normes de transcription précitées, avec quelques ajustements en fonction de la spécificité des sources traitées. Ces corpus représentent une ressource précieuse pour l’entraînement de modèles d’ATR et ont permis l’entraînement de modèles génériques80 :
-
Gallicorpora+, pour les imprimés français du xvie au xixe siècle81 ;
-
CATMuS Medieval, modèle multilingue pour les manuscrits médiévaux compris entre le xe et le xve siècle82 ;
-
HTR-United - Manu McFrench pour les écritures manuscrites modernes françaises83.
Lors de l’utilisation d’un modèle HTR, il est crucial de prendre en compte la technologie sous-jacente, la compatibilité d’environnement et les scores de précision. Ces scores sont dérivés de la capacité du modèle à prédire une transcription sur un échantillon des données d’entraînement réservées à cette fin. La composition du corpus d’entraînement doit être soigneusement considérée pour interpréter correctement le score. Plus le corpus est homogène, plus les scores peuvent être élevés, même avec un corpus d’entraînement restreint, car la précision est évaluée sur un échantillon très similaire au corpus d’entraînement. À l’inverse, plus un corpus est hétérogène, plus les scores élevés deviennent difficiles à atteindre, mais cela augmente les capacités du modèle à fonctionner sur un corpus inconnu. Les modèles génériques, tels que ceux mentionnés précédemment, conçus pour être utilisés sur de nouveaux corpus, peuvent également être affinés pour répondre à des besoins spécifiques avec un investissement relativement faible en données d’entraînement84. Ainsi, le défi actuel consiste à élaborer des modèles génériques capables de traiter des sources les plus variées possibles, objectif que le projet CATMuS85 tente de relever en développant des modèles multilingues couvrant une vaste période historique.
Les chaînes d’acquisition textuelle
L’acquisition automatique de texte à partir de sources numérisées a profondément transformé le rôle de l’éditeur dans la production du texte numérique. La capacité d’acquérir des textes à grande échelle, y compris ceux d’origine manuscrite, a conduit les projets de recherche à aborder des corpus de plus en plus vastes. En outre, l’assise actuelle du standard XML TEI facilite l’émergence de protocoles de publication en ligne86, notamment avec l’apparition de TEIPublisher87 qui s’appuie sur la modélisation des données en TEI. Enfin, la démocratisation d’outils comme eScriptorium ou Trankribus a également favorisé la mise en place de protocoles pour transformer les XML ALTO de l’ATR en XML TEI en vue de la mise en ligne des corpus88. Le projet DiScholEd illustre cette dynamique en visant à établir un protocole facilitant la production de textes et d’éditions en ligne à partir de leur numérisation89. Ainsi, l’édition en ligne de la Correspondance de Constance de Salm90, dont le texte a été acquis automatiquement, propose un système de navigation, une édition critique et une édition diplomatique, ainsi qu’un travail sur les entités nommées, avec un accès facilité aux index et à des cartes. La flexibilité de cette approche et son adaptabilité à la source permettent de proposer des protocoles communs tout en évitant une standardisation excessive de l’interface qui ne serait pas en accord avec l’interprétation proposée par l’éditeur91.
Les chaînes d’acquisition textuelle, intégrant une étape d’ATR ou non, peuvent être agrémentées d’une série de normalisations et d’enrichissements générés automatiquement92, comprenant le développement des abréviations, la normalisation de la segmentation des mots, l’annotation linguistique et des entités nommées, l’ajout de métadonnées et proposer un balisage automatique vers la TEI en s’appuyant sur les informations de mise en page produites lors de l’ATR93 (voir figure 2) pour optimiser la hiérarchisation, l’enrichissement et la fouille du texte.
Le projet Gallic(opor)a94 illustre ces ambitions, bien que seuls les objectifs liés à l’ATR et à la pré-éditorialisation en TEI aient pu être atteints dans le cadre du financement initial.
Figure 2 : Exemple de protocole, issu de Ariane Pinche, « Guide de transcription pour les manuscrits du Xe au XVe siècle », 2022
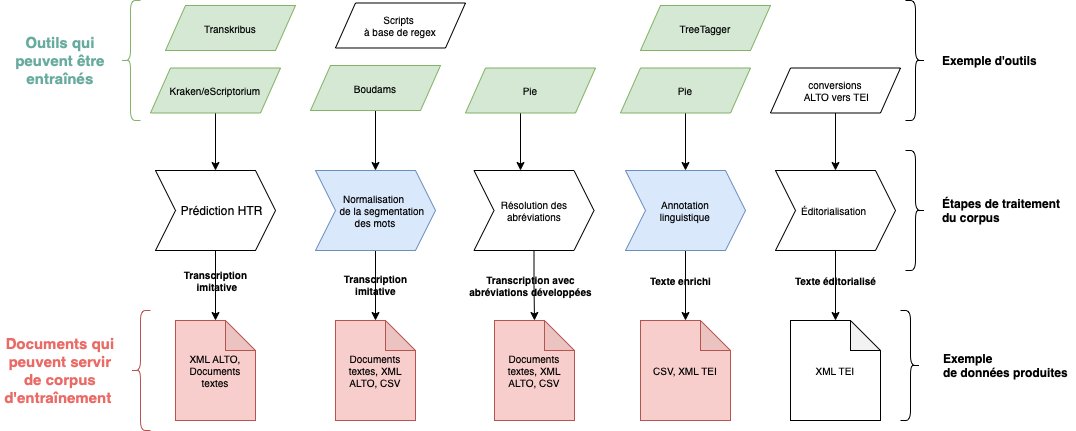
Des initiatives plus récentes, telles que la thèse de Matthias Gille Levenson95, explorent des chaînes éditoriales semi-automatiques incluant une assistance à la collation. Son logiciel, teiCollator96, décompose le processus en plusieurs étapes, de la transcription du témoin à la réalisation d’une édition critique consultable en PDF via LaTeX.
Figure 3 : Chaîne de traitement des données dans le projet Gallic(orpor)a, issue d’Ariane Pinche, Kelly Christensen et Simon Gabay, « Between automatic and manual encoding Towards a generic TEI model for historical prints and manuscripts », TEI Conference and Members&apos ; Meeting, Newcastle, 2022.
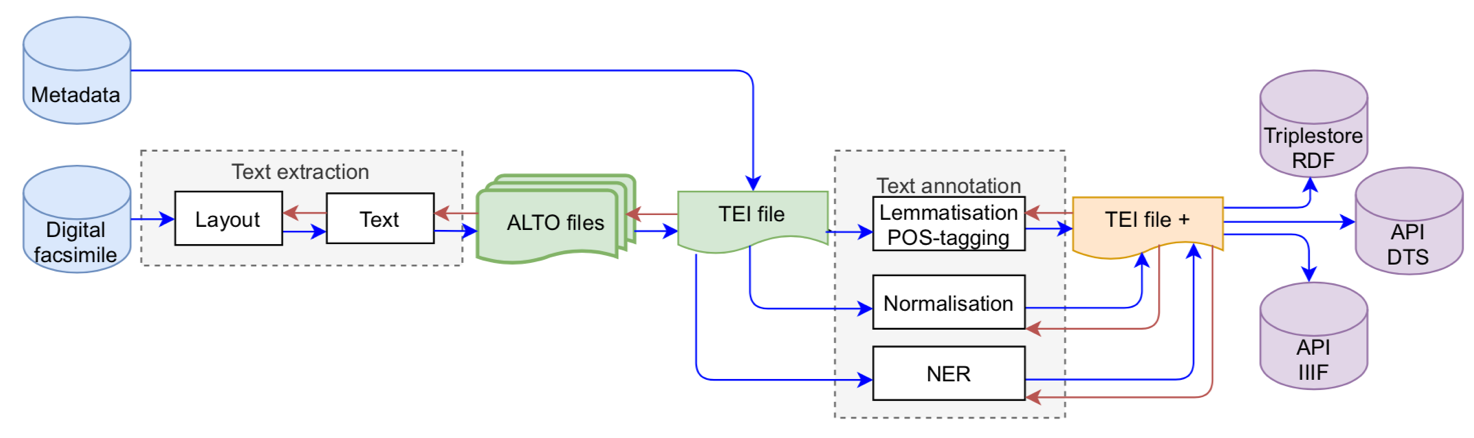
Ainsi, l’évolution rapide des techniques d’ATR et des chaînes éditoriales numériques redéfinit le paysage de l’édition, plaçant l’éditeur au cœur d’une démarche de traitement de vastes corpus. L’acquisition automatisée permet désormais d’explorer des textes, qu’ils soient originalement imprimés ou manuscrits, à une échelle inédite, qui appelle une évolution des pratiques éditoriales. Les chaînes éditoriales, de plus en plus sophistiquées, englobent des métadonnées variées et des outils automatisés, créant ainsi un écosystème éditorial plus complet. En outre, l’éditeur, désormais confronté à des corpus de grande envergure, est invité à collaborer avec des experts en intelligence artificielle, traitement automatique du langage, et autres domaines connexes. Cette évolution, loin de reléguer la philologie traditionnelle au second plan, offre l’opportunité de construire des méthodes éditoriales solides, tout en explorant des approches de lecture adaptées à divers profils d’utilisateurs. Ainsi, en embrassant ces transformations, l’éditeur peut non seulement relever les défis de l’ère numérique, mais également contribuer activement à l’élaboration d’une édition numérique accessible, riche et en constante évolution.
Les évolutions marquantes et les débats philologiques ont façonné l’édition numérique depuis les années quatre-vingt jusqu’à nos jours97. Tout au long de cette analyse, nous avons souligné la pertinence de l’édition numérique dans les débats philologiques. Notre examen a mis en lumière les modifications induites par les innovations techniques, transformant la perception du texte et redéfinissant l’objet éditorial. Cependant, ces avancées n’ont pas été sans susciter de nouvelles difficultés, perturbant des méthodes séculaires et demandant encore aujourd’hui de réfléchir à l’évaluation, la pérennisation, l’accessibilité et la citabilité des éditions numériques. Enfin, nous espérons avoir montré comment le passage au format numérique, suivi de l’émergence des chaînes éditoriales automatisées, représente aujourd’hui une opportunité inédite. Cette évolution permet la constitution de corpus d’une ampleur sans précédent et facilite l’accès aux textes, répondant ainsi aux besoins d’un public toujours plus vaste. Toutefois, cette transition souligne également la nécessité de continuer à adapter nos pratiques et réflexions aux défis posés par ces nouvelles méthodologies, afin de garantir la qualité des éditions numériques dans le paysage académique.