
Introduction
L’utilisation des méthodes de reconnaissance automatique dans les projets d’éditions notamment numériques gagne de plus en plus en importance dans les sciences humaines et sociales. À partir du projet d’édition en cours « Grand Tour digital », cet article propose un retour d’expérience : il souhaite mettre en avant les méthodes mobilisées et discuter les possibilités et les limites qui sont progressivement apparues1. Réalisé à la Herzog August Bibliothek à Wolfenbüttel (HAB) en Allemagne, ce projet a pour but de numériser, d’exploiter et de visualiser des témoignages de voyage de formation ou du Grand Tour à l’aide des méthodes d’édition semi-automatiques.
Traitant un corpus d’une vingtaine de récits de voyage de l’époque moderne qui sont principalement conservés dans les fonds de la bibliothèque, le projet recourt à la plateforme de reconnaissance de texte et d’écriture manuscrite automatique Transkribus. Il apparaît que si cet outil est en mesure de faire face à un certain nombre de défis, la qualité de la numérisation dépend néanmoins fortement de l’état des manuscrits.
Le projet « Grand Tour digital »
Enjeux et buts du projet
À l’époque moderne, les voyages éducatifs tels que le Grand Tour étaient une étape cruciale dans le développement personnel des membres des élites nobles et bourgeoises. Leur signification particulière, jusqu’à présent peu étudiée dans la recherche sur les témoignages personnels (Selbstzeugnisforschung), réside dans le fait qu’ils capturaient et évaluaient moins les expériences en tant qu’altérité, mais mettaient plutôt en avant la réussite de la gestion des expériences dans des environnements étrangers. Ce type de témoignages personnels fait l’objet du projet d’édition « Grand Tour digital. Digitalisierung, Erschließung und Visualisierung frühneuzeitlicher Selbstzeugnisse von Bildungsreisen unter Anwendung teilautomatisierter Editionsverfahren2 », soutenu financièrement par la Deutsche Forschungsgemeinschaft (DFG), de 2022 à 2025.
Employée dans le nom du projet, la notion de « Grand Tour » est utilisée dans un sens large. Par conséquent, le corpus de sources ne se limite pas uniquement aux récits du Grand Tour classique qui emmenait les voyageurs en France et surtout en Italie, mais inclut également d’autres voyages, tels les tournées à cheval des nobles-patriciens (adlig-patriziche Kavarlierstour), les pérégrinations académiques étudiantes (studentische peregrinatio academica) et les voyages savants professoraux, comme ceux distingués par Mathis Leibeteseder3. Ces distinctions permettent de classer ces témoignages personnels rendus disponibles à travers leurs numérisations. Les textes édités seront mis à disposition au cours du projet sur le portail des témoignages personnels (Selbstzeugnisportal) de la HAB4. Le travail est documenté dans un blog accompagnant le projet5, et une offre ultérieure pour la réutilisation du modèle HTR, des textes et des données de recherche sera également disponible via le serveur GitLab6 de la HAB.
Corpus des sources
Au cœur du projet se trouvent 21 journaux de voyage, principalement rédigés en allemand entre les années 1550 et 1770 (pour un total d’environ 10 300 pages). Ils proposent des récits de voyage dans toute l’Europe et jusqu’à l’Empire ottoman et le Proche-Orient (Alep, Jérusalem). Ces journaux sont conservés principalement à la HAB à l’exception de deux manuscrits qui se trouvent aux Archives d’État de Basse-Saxe (Niedersächsisches Landesarchiv) à Wolfenbüttel.
Le projet s’intéresse particulièrement à cinq textes, dont l’un est accompagné de trois transcriptions, qui seront transcrits de manière partiellement automatisée grâce au logiciel de reconnaissance d’écriture manuscrite Transkribus, puis encodés en TEI-XML. L’utilisation de la reconnaissance d’entités nommées (Named Entity Recognition, REN) permet leur exploration, et leur visualisation est réalisée en combinant le texte avec l’itinéraire du voyage. Cette approche vise à expérimenter le développement d’un processus éditorial novateur.
Ces cinq récits ont été rédigés par les personnes suivantes :
-
Barthold von Gadenstedt (HAB Cod. Guelf. 67.6 Extrav.)
-
Le pharmacien Wagener (HAB Cod. Guelf. 267.1 Extrav.)
-
Christian August de Schleswig-Holstein-Norburg (HAB Cod. Guelf. 221 Extrav.)
-
Ernst Ferdinand et Heinrich Ferdinand de Brunswick-Wolfenbüttel-Bevern7 (HAB Cod. Guelf. 149.14 Extrav.)
-
Ludwig Rudolph de Brunswick-Wolfenbüttel (HAB Cod. Guelf. 89 Blank.)
S’ajoutent à cela 13 récits de voyage supplémentaires, qui sont numérisés. Leurs métadonnées sont explorées et seront mises à disposition via la base de données des manuscrits de la bibliothèque8.
La reconnaissance automatique des récits de voyage avec l’outil Transkribus
La quantité de projets éditoriaux utilisant des logiciels de reconnaissance manuscrite, dont Transkribus, a augmenté de manière significative ces dernières années9. L’application de méthodes d’intelligence artificielle offre une nouvelle approche pour interagir avec et traiter des sources historiques, qu’elles soient imprimées ou manuscrites.
Transkribus est une plateforme dédiée à la transcription automatique, à l’analyse d’images et à la reconnaissance de structures de documents historiques grâce à l’intelligence artificielle. Le programme a été développé à la suite de deux projets consécutifs à l’Université d’Innsbruck : « tranScriptorium », de 2013 à 2015, et « READ » (Recognition and Enrichment of Archival Documents), de 2016 à 2019. Pour l’utilisateur, il est possible d’utiliser Transkribus soit via l’application téléchargeable sur le bureau, soit en ligne avec Transkribus Lite. L’inscription et l’utilisation sont gratuites, mais pour la transcription automatisée, l’utilisateur dispose d’un quota spécifique de « crédits ». Après leur épuisement, il peut en acheter de nouveaux dans différents packs.
Transkribus propose de nombreux modèles d’intelligence artificielle (IA) disponibles gratuitement. En janvier 2024, on en compte 138 créés pour des sources manuscrites et imprimées de différentes périodes, ainsi que pour de nombreuses langues européennes et extra-européennes. Pour ce projet, comment choisir le modèle qui convient à cette écriture manuscrite ? Quels critères sont importants, voire convaincants, pour la sélection du modèle de base ? Et pourquoi créer un nouveau modèle pour les écritures de la période moderne, alors que plusieurs modèles sont déjà disponibles10 ?
Transkribus fait face à divers défis lors de la transcription automatisée de récits de voyage de l’époque moderne, tels que celui de Wagener, mais ces défis sont également applicables de manière générale aux témoignages personnels de cette époque :
-
Aspect de l’écriture et lisibilité : la qualité de la transcription dépend fortement de la forme de l’écriture, qui elle-même varie en fonction de la version originale ou d’une copie, ainsi que de l’état de conservation de la source.
-
Écriture individuelle : chaque individu a une écriture unique. Les fautes d’orthographe, les ratures, les ajouts, ainsi que l’encre étalée, pressée ou décolorée compliquent la reconnaissance automatisée.
-
Mise en page variée : les récits de voyage de l’époque moderne présentent souvent une mise en page variée, incluant le texte principal, des annotations marginales, des tableaux, des listes, des schémas ainsi que des esquisses de taille différente. S’ajoutent de manière répétée des compléments et corrections ultérieurs directement dans le corpus du texte, qui sont soit ajoutés en marge du texte, soit insérés entre les lignes.
-
Polices et tailles de caractères variées : un texte peut contenir différentes polices et tailles de caractères, comprenant notamment la cursive allemande, l’écriture latine, ou d’autres encore.
-
Utilisation de différentes langues : l’inclusion de différentes langues, comme des copies d’inscriptions ou des citations, représente un défi supplémentaire et peut demander au modèle d’être entraîné sur plusieurs langues.
-
Exigences de contenu : les récits de voyage de l’époque moderne contiennent souvent un grand nombre de noms propres (personnes, lieux, œuvres d’art, titres de livres, etc.), des indications de date, des mesures et des caractères spéciaux qui doivent être précisément identifiés et transcrits.
Dans le cadre du projet sera développé un modèle entraîné à ces exigences qui sera partagé en accès libre à son achèvement.
À propos de l’application de Transkribus et le workflow élaboré
Créer un premier modèle de reconnaissance de textes
L’objectif central du projet « Grand Tour digital » est la mise au point expérimentale d’un processus éditorial novateur en utilisant Transkribus. Le logiciel lui-même fournit de nombreuses instructions utiles pour l’édition de texte11. En outre, la recherche produit de plus en plus de rapports d’expérience, de discussions scientifiques et de conseils pratiques sur cet outil12.
Lors d’une première étape, après avoir transcrit manuellement une vingtaine des pages du journal de voyage de Wagener dans Transkribus, on a pu partir des pages saisies et d’un modèle déjà existant pour permettre l’entraînement d’un nouveau modèle. Pour sa création, nous avons choisi le modèle existant « Transkribus German handwriting M1 » avec une faible erreur ou taux d’erreur de caractères (CER)13 de 4,70 % comme modèle de base. Ce modèle a été réentraîné à partir de la transcription manuelle des premières pages (p. 7 à 26).
Une fois entraîné, ce modèle a été appliqué aux autres pages du manuscrit et ajusté dans des étapes alternées de transcription partiellement automatisée, de correction et de nouvel entraînement du modèle. L’idée centrale derrière ces étapes de travail était d’adapter le programme aux particularités de l’écriture de Wagener afin de réduire progressivement le taux d’erreur dans la reconnaissance manuscrite au cours de la transcription du texte. Dans cette perspective, il est important de comprendre les caractéristiques spécifiques du manuscrit qui a composé cette première base de départ. En ce qui concerne l’indexation du texte partiellement automatisée dans Transkribus, le manuscrit présente généralement une écriture claire avec peu de ratures ou d’ajouts. Parfois, l’encre a traversé le papier, ce qui rend la lecture du manuscrit difficile tant pour l’homme que pour la machine. À certains endroits de son récit de voyage, Wagener a également ajouté des notes sur de petits morceaux de papier collés à l’intérieur de son journal. La langue du texte est principalement l’allemand, mais on trouve à plusieurs reprises des citations transcrites d’inscriptions en français et en latin, surtout à la fin du récit14.
Pour au mieux réussir la transcription automatisée dans Transkribus, le texte a été préparé de manière à minimiser autant que possible les erreurs de détection des champs de texte. À cette fin, le marquage des champs de texte peut soit être parcouru automatiquement et corrigé par la suite, soit être créé directement manuellement. Selon le manuscrit, l’une ou l’autre option est recommandée pour travailler de manière aussi efficace que possible. Dans le cas du manuscrit de Wagener, le marquage automatique des champs de texte a été effectué pour les pages restantes du manuscrit, puis, lors de l’examen ultérieur, de petites corrections ont été apportées en cas d’erreurs dans le marquage du texte principal et des notes en marge ainsi que des lignes manquantes ont été ajoutées. Ce travail se fait plus difficile lorsque les champs de texte ou même les mots se chevauchent et se superposent, mais il est également possible de corriger le tout manuellement dans ce cas.
Lors de l’entraînement d’un nouveau modèle, Transkribus distingue entre les pages d’entraînement et de validation. Les pages d’entraînement lors du premier passage (p. 7 à 21) étaient celles où le modèle était formé et les pages de validation (p. 22 à 26) étaient celles où le modèle était automatiquement vérifié et le taux d’erreur calculé15. Au cours de cette première itération, l’ensemble d’entraînement, associé au modèle de base avait atteint un taux d’erreur de 2,41 %. Les pages de validation, idéalement représentatives des particularités du manuscrit, avaient un taux d’erreur de 11 %. Afin d’optimiser les résultats sur les pages de validation lors des ajustements ultérieurs du modèle, des pages de manuscrit non consécutives ont été sélectionnées à intervalles réguliers (par exemple, par intervalles de cinq pages). Les 86 pages restant à traiter ont été lues automatiquement par Transkribus par tranches d’environ 20 pages chacune, puis corrigées manuellement et réentraînées avec les pages précédentes. En cas de pages fortement variables, il est également possible – à l’instar de la suggestion et de la documentation de Jacob Möhrke dans son rapport d’atelier – de trier les pages de manuscrit en fonction de leur qualité textuelle et de retirer du jeu d’entraînement les pages qualifiées de « non utilisables16 ». Ce processus itératif visait à optimiser progressivement le modèle de transcription.
Le logiciel Transkribus propose lui-même une vue d’ensemble du jeu de caractères (character set) entraîné pour chaque modèle formé. Pour le manuscrit de Wagener, les caractères suivants ont fait sujet de l’entraînement :
Fig. 1. Vue d’ensemble des signes entraînés dans Transkribus à l’aide des premières pages du manuscrit Wagener.
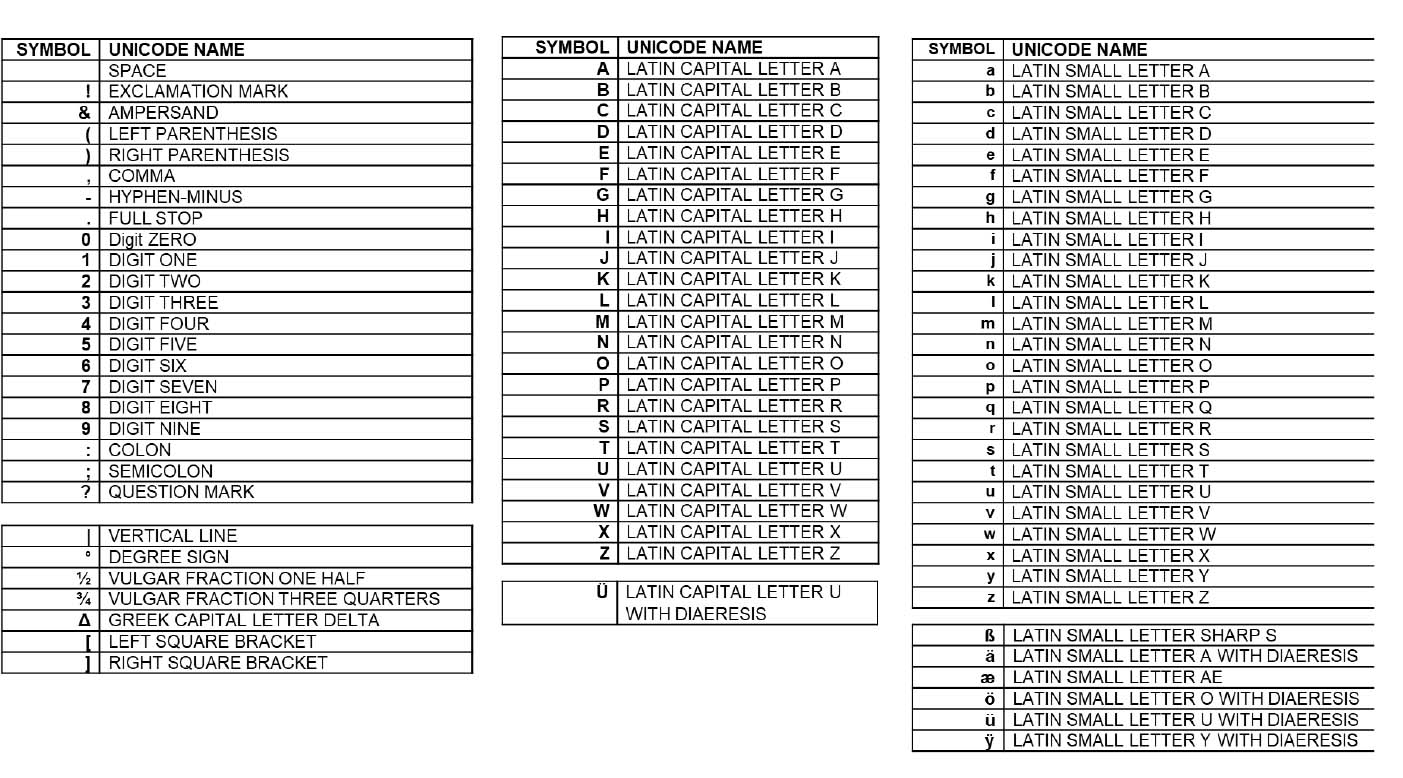
Cette vue d’ensemble ne couvre pas tous les caractères possibles de l’écriture cursive latine, mais se limite aux seuls caractères utilisés dans le manuscrit. Cependant, il n’est pas tout à fait évident de savoir si cette liste inclut également des caractères du modèle de base sélectionné, dans notre cas « Transkribus German Handwriting M1 », ou si elle se limite exclusivement aux premières 26 pages du manuscrit de Wagener. Malheureusement, dans la présentation du modèle, il n’existe pas de référence explicite au modèle de base et des informations approfondies sur ce dernier font défaut, rendant une analyse plus approfondie et une meilleure compréhension de la procédure difficile.
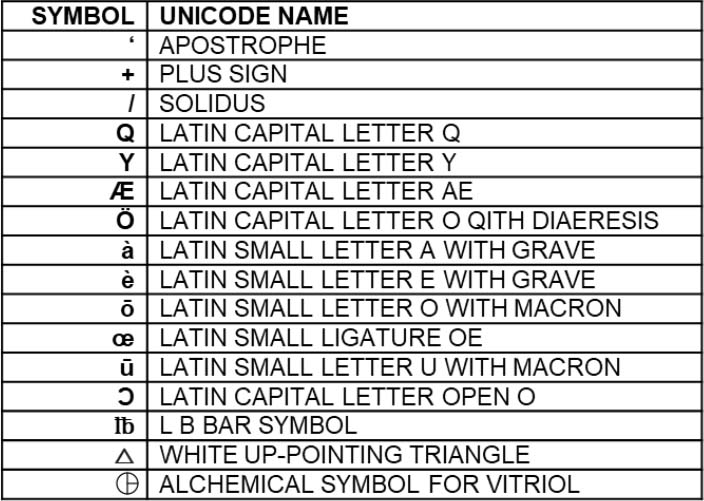
Le jeu de caractères généré lors de la première formation avec Transkribus a été élargi et complété avec des caractères manquants au cours des formations et ajustements ultérieurs :
Fig. 2. Vue d’ensemble des signes rajoutés lors des entrainements supplémentaires du modèle HTR.
En résumé, lors de la formation du modèle sur l’exemple du manuscrit Wagener, les courbes d’apprentissage suivantes se sont développées :
Fig. 3. Vue des cinq courbes d’apprentissage réalisées lors des entraînements du modèle au manuscrit Wagener. De gauche en haut à droite en bas chaque courbe représente un entrainement.
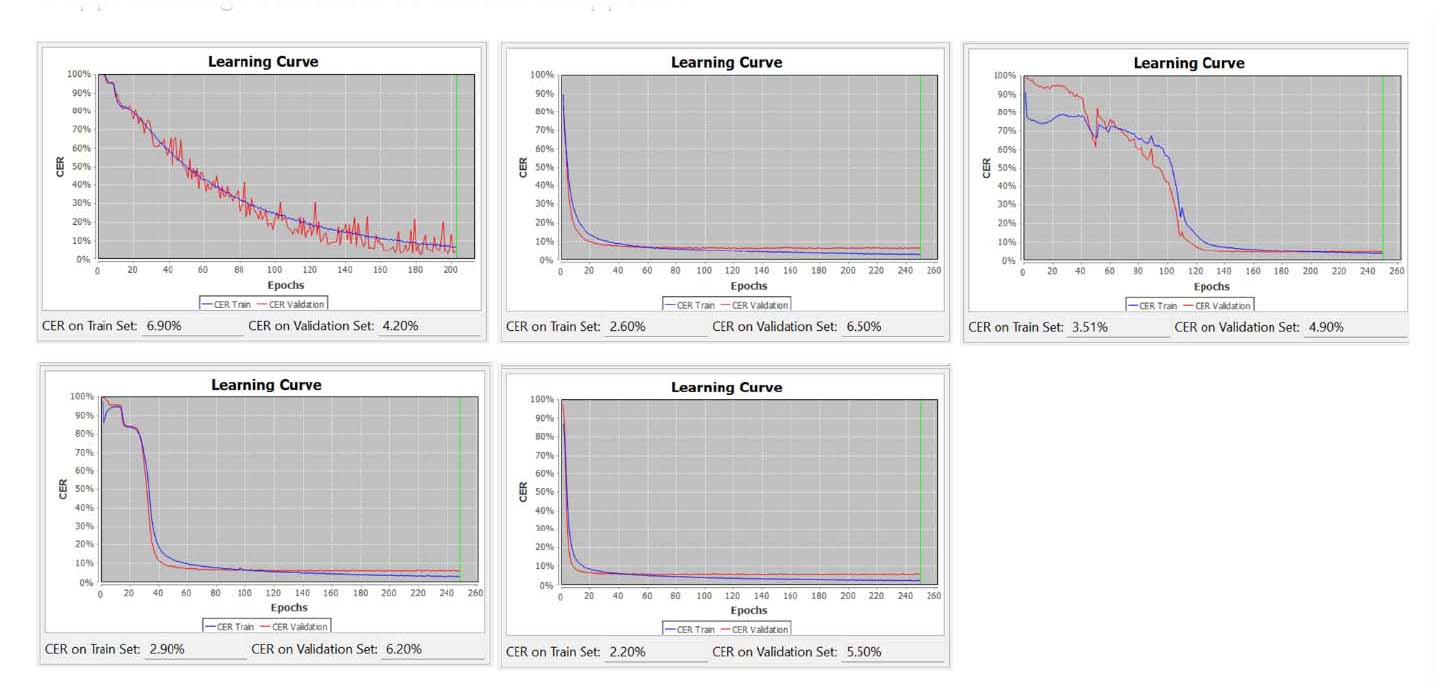
Cette optimisation du modèle fonctionne-t-elle ? D’après les courbes d’apprentissage, une amélioration réelle n’a pas été totale, voire elle a échoué, mais pour quelles raisons ? Les courbes d’apprentissage démontrent une fois de plus que la qualité et le succès ou l’échec de la reconnaissance manuscrite dépendent fortement des pages et soulignent également qu’une sélection liée la qualité de certaines pages pour l’entraînement du modèle serait avantageuse. Une amélioration progressive du modèle n’est pas clairement perceptible dans le cas de l’écriture manuscrite de Wagener – le taux d’erreur, en particulier pour les pages de validation, fluctue entre 4 et 6 %. C’est encore nettement trop élevé dans tous les cas. Cependant, pour les pages d’entraînement, elle diminue de 7 % à environ 2 %. À la lumière de ces premiers résultats, deux questions se posent pour le traitement continu du texte : comment le résultat de l’entraînement du modèle diffère-t-il du résultat de l’application du modèle ? Y a-t-il un meilleur apprentissage en répétant l’entraînement de l’écriture manuscrite en éliminant les pages « inutilisables », ou altère-t-on progressivement le résultat global de cette manière ?
Au regard de ces questions, il est intéressant de savoir s’il peut y avoir une amélioration au cours du traitement ultérieur des autres manuscrits avec ce même modèle et si cette amélioration dépendra de l’inclusion ou de l’exclusion de certaines pages de manuscrit. En réalité, le développement des courbes d’apprentissage pour le premier manuscrit n’a pas toujours été optimal et offre encore suffisamment d’espace pour une amélioration dans le cadre du travail continu de ce projet.
Évaluer la transcription automatique
Finalement, qu’est-ce qui a bien fonctionné, qu’est-ce qui n’a pas fonctionné ? Quels problèmes ont été identifiés et quelles solutions Transkribus propose-t-il ? Des évaluations comparables de transcriptions automatisées ont déjà été réalisées dans le cadre d’autres projets et les contributions scientifiques qui en ont résulté soulignent les opportunités de succès ainsi que les difficultés, telles que la dépendance à l’égard de la forme de l’écriture ou le risque de surapprentissage d’un modèle17.
Les insights tirés de divers projets et manuscrits sur lesquels Transkribus a été testé montrent clairement que même avec des modèles bien entraînés, une précision de reconnaissance manuscrite à 100 % ne peut jamais être atteinte par une IA : « La reconnaissance automatique de l’écriture manuscrite conduira à un taux d’erreur même avec des modèles bien entraînés. Ainsi, aucun texte philologiquement irréprochable ne sera généré sans correction manuelle ultérieure (post-traitement)18 ».
À partir du manuscrit de Wagener, nous avons pu examiner plus précisément l’évaluation dans Transkribus, présenter et remettre en question les possibilités d’évaluation automatisée des résultats, identifier les types d’erreurs et discuter de leurs causes possibles. Transkribus offre lui-même la possibilité d’évaluer la transcription effectuée directement dans le programme. Il convient de faire la distinction entre l’évaluation du taux d’erreur (CER) sur les pages de test et de validation et l’application du modèle entraîné sur les autres pages du manuscrit. La précision de la transcription peut être calculée à différents niveaux. Pour la comparaison, deux variantes de texte doivent être sélectionnées. Il faut d’abord une « Référence », un texte correct servant de référence pour l’identification des erreurs. Transkribus recommande « [e]n tant que Référence, choisissez une version de page qui a été correctement transcrite (Ground Truth : transcription manuelle aussi proche que possible du texte original). Pour obtenir la valeur la plus significative, il serait préférable d’utiliser des pages d’un ensemble d’échantillons qui n’ont pas été utilisées dans l’entraînement et qui sont donc nouvelles pour le modèle19 ». Pour Wagener, nous avons utilisé la version corrigée la plus récente, qui est la plus proche du manuscrit du point de vue orthographique.
En regard de ce texte de référence, il faut établir une « hypothèse », c’est-à-dire le texte « hypothétique » à comparer avec la variante correcte. Cela peut être la transcription automatisée par Transkribus, mais aussi des variantes textuelles ultérieures, afin d ’examiner ou de suivre certaines corrections entre collaborateurs. Transkribus recommande » en tant qu’Hypothèse, choisissez la version qui a été générée automatiquement avec un modèle de reconnaissance de texte manuscrit (HTR) et sur laquelle vous aimeriez voir à quel point le résultat est satisfaisant20 ». Ainsi, nous avons choisi la reconnaissance de texte automatisée (décodage PyLaia). La possibilité offerte par Transkribus de comparer différentes versions de traitement de texte permet une confrontation directe entre la transcription partiellement automatisée et la correction manuelle effectuée. Cependant, il est difficile de comprendre exactement comment fonctionnent la comparaison et l’évaluation qui en découle. Contrairement à d’autres programmes de reconnaissance de texte manuscrit, cela n’est pas transparent dans le cas de Transkribus.
Les problèmes rencontrés lors de l’évaluation automatique concernent principalement la détection des lignes, surtout lorsqu’elle est corrigée ultérieurement ou lorsqu’il y a des améliorations dans l’ordre des lignes. Par exemple, les lignes peuvent être difficile à identifier si l’une d’entre elles est divisée en deux et que les deux éléments sont fusionnés, si une note est ajoutée au-dessus de la ligne, ou si une note en marge est séparée du texte principal après coup. Dans ces cas, l’ensemble du texte se déplace, ce qui entraîne également des parties considérées comme incorrectes ou affichées comme telles, bien qu’elles soient au moins partiellement correctes. En effet, Transkribus prétend attribuer une erreur à chaque caractère mal reconnu.
Fig. 4. Les deux captures d’écran montrent le résultat de la transcription automatique le plus réussi (à gauche) et le plus mauvais (à droite) [Des corrections ultérieures n’ont pas pu être prises en compte ici]
![Fig. 4. Les deux captures d’écran montrent le résultat de la transcription automatique le plus réussi (à gauche) et le plus mauvais (à droite) [Des corrections ultérieures n’ont pas pu être prises en compte ici]](docannexe/image/129/img-4.jpg)
Dans cette perspective, un problème supplémentaire d’évaluation avec Transkribus est lié au fait que le système se base sur les mots et non sur les caractères individuels. Pour un observateur extérieur, les résultats semblent donc plutôt moyens, même s’ils sont en réalité nettement meilleurs. On le comprend lorsque l’on compare l’évaluation de l’écriture manuscrite de Wagener au niveau des mots et des caractères : au niveau des mots, le taux d’erreur est généralement plus élevé qu’au niveau des caractères.
Étant donné que Transkribus fournit l’évaluation automatique de la transcription au niveau des caractères et alors que pour les mots il le fait uniquement en pourcentages, nous avons effectué une évaluation manuelle de la transcription automatisée et nous avons compté les pages. Lors de l’évaluation manuelle de la transcription, nous avons veillé à compter toutes les reconnaissances divergentes. L’objectif était de découvrir et de comprendre la fiabilité de l’évaluation automatisée de Transkribus. Ce qui est étonnant, c’est qu’apparaissent des écarts significatifs dans les pourcentages. Ainsi, la somme des valeurs, que ce soit pour le taux d’erreur de mots (WER) et la précision des mots, ou pour le taux d’erreur de caractères (CER) et la précision des caractères, n’a pas atteint les 100 %. Il est également frappant de noter que les valeurs lors de l’évaluation du taux d’erreur de mots (WER) dans l’évaluation automatisée correspondent approximativement à mes propres calculs ; cependant, au niveau des caractères, Transkribus présente un taux d’erreur de caractères de 41,66 %, alors qu’après le calcul manuel, seulement près de 17 % des caractères ont été mal lus. De plus, le résultat global est meilleur que ce que Transkribus avait prévu. Ainsi, pour l’écriture manuscrite de Wagener, nous avons atteint une précision d’à peine 58 % au niveau des mots mais à plus de 80 % au niveau des caractères. En tenant compte du faible nombre de pages de l’écriture manuscrite de Wagener sur lesquelles Transkribus a pu apprendre, le résultat obtenu ici est déjà bon, bien qu’il reste possible et souhaitable de l’améliorer davantage.
En plus de l’affichage de la fréquence des erreurs, une évaluation des pages manuscrites individuelles au niveau des mots et des caractères offre un aperçu plus précis du déroulement et des résultats des différentes itérations d’entraînement du modèle. Le nouveau cycle d’entraînement du modèle a-t-il été bénéfique ? Comment le résultat de la transcription se compare-t-il avec le taux d’erreur prédéfini dans l’ensemble d’entraînement et de validation ?
Lorsqu’on examine les résultats de la transcription partiellement automatisée, une analyse plus approfondie des erreurs survenues (types d’erreurs) est recommandée. Cela inclut notamment des lectures complètement erronées de mots et parfois même de lignes entières, qui déformaient le contenu ou le rendaient méconnaissable, rendant ainsi la lecture du manuscrit plus difficile. Comme mentionné précédemment, ces erreurs dépendaient fortement des pages et étaient causées par l’apparence de l’écriture, l’encre détrempée, des ajouts de mots isolés ou des ratures qui n’étaient généralement pas reconnus par le programme. Sur certaines pages, les erreurs étaient également causées par des petits morceaux de papier mal reliés, qui ne posaient généralement pas de problème à la reconnaissance des champs de texte par le logiciel, mais qui compliquaient la reconnaissance des caractères21. Dans l’ensemble, des lignes entières étaient souvent mal lues, transcrivant une séquence de lettres incompréhensible, tandis que des lignes entièrement lues sans erreur étaient plutôt l’exception.
En général, les erreurs concernaient souvent des lettres individuelles (notamment la confusion entre u/v, s/f, m/n, c/e, b/l, etc.), des signes de ponctuation (virgules manquantes ou mal lues, ponctuations, parenthèses) ou des espaces mal lus, trop peu ou trop nombreux. Certaines lettres ont été lues en double, d’autres ont été ignorées ; la quantité de caractères dans la version corrigée ne correspondait pas toujours à celle de la version lue automatiquement. Parfois, des signes de ponctuation ont été identifiés comme des lettres et vice versa, parfois l’ordre a été inversé ou mélangé, par exemple, « wire » au lieu de « wier ». Certaines erreurs étaient malheureusement dues uniquement à des espaces manquants, supplémentaires ou inutiles. Moins graves sont également les erreurs liées aux accents et aux trémas. Il est à noter que le logiciel n’a presque pas reconnu les soulignements, les mises en évidence, les ratures, les élévations et les indices de caractères individuels. Cela peut cependant être dû au fait que les zones de texte précédemment marquées n’ont pas nécessairement été incluses dans l’entraînement du modèle et la tâche de reconnaissance manuscrite partiellement automatisée en tant que telle. En ce qui concerne les caractères spéciaux, le programme a appris au fil de l’ajustement du modèle et s’est amélioré. Les caractères étaient généralement bien lus (par exemple, dans les indications de quantités) et seulement quelques erreurs sont survenues. Dans l’ensemble, la reconnaissance des dates et des chiffres généraux était défectueuse.
Le modèle a pu être optimisé au fil de son utilisation ultérieure sur des manuscrits subséquents, atteignant jusqu’à présent un taux d’erreur de 0,70 % dans l’ensemble d’entraînement et 2,60 % dans l’ensemble de validation.
Fig. 5. La capture d’écran montre comme exemple le résultat de la transcription automatique du manuscrit HAB Cod. Guelf. 256.1 Extrait à l’aide de l’application du modèle de Wagener.
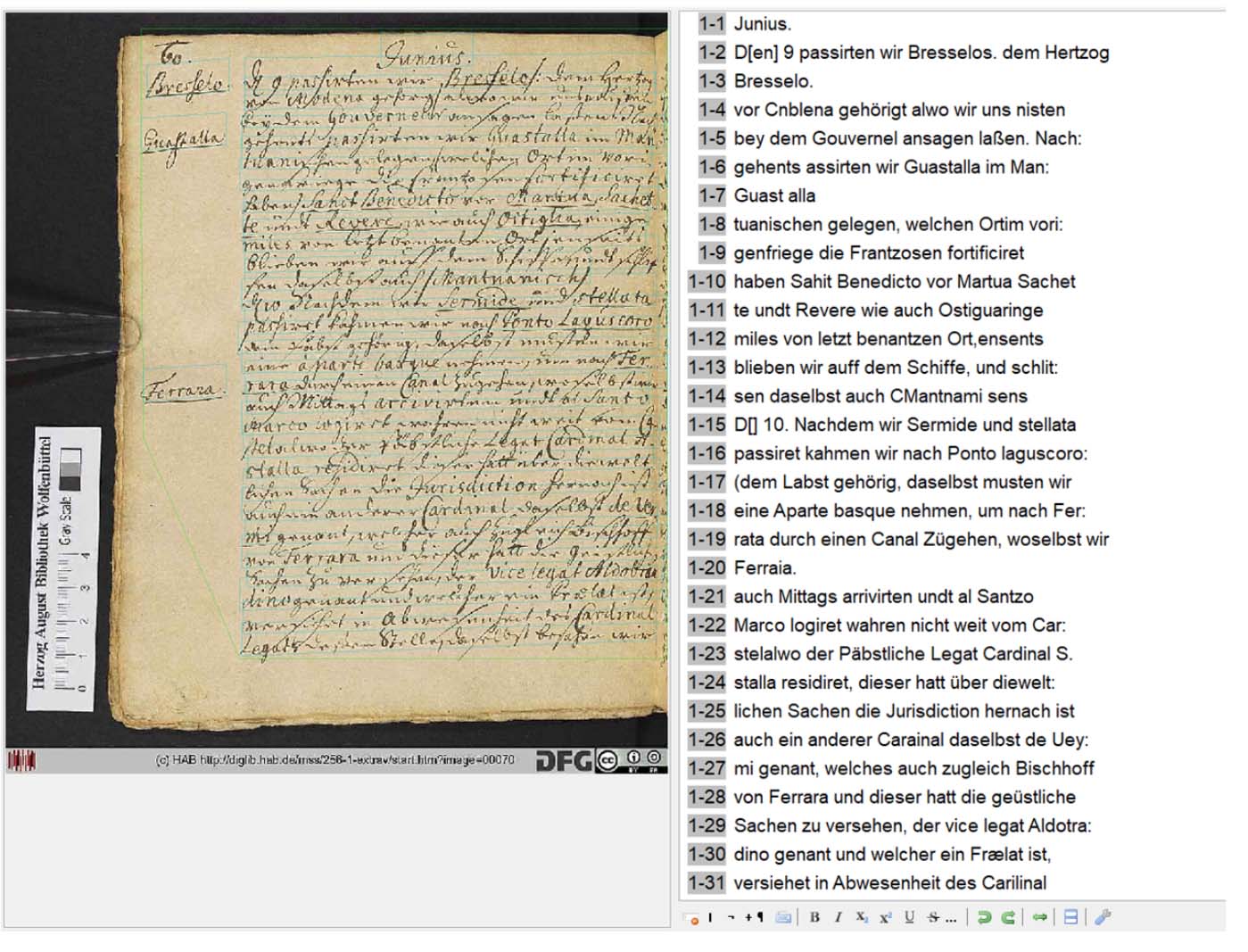
Cependant, Transkribus atteint rapidement ses limites. Des ajustements échouent lorsque le programme ne peut plus améliorer la reconnaissance d’une écriture manuscrite. Les entraînements n’aboutissent alors pas : dans les ensembles d’entraînement et de validation, apparaissent des taux d’erreur inexplicables et élevés, dépassant parfois les 80 %, voire les 90 %. Lorsque de tels échecs surviennent, aucune amélioration supplémentaire n’est possible et il faut revenir au modèle précédemment entraîné ayant obtenu les meilleurs résultats.
À propos des possibilités et limites de Transkribus
Comme le montre l’exemple du manuscrit de Wagener, le succès d’une reconnaissance automatisée de l’écriture manuscrite dépend fortement de chaque page et de la ligne transcrite. De plus, la lisibilité et la qualité du scan du manuscrit, ainsi que la présence de ratures et d’ajouts (notamment entre deux lignes), sont d’une importance particulière pour le succès de la reconnaissance automatisée de l’écriture manuscrite et peuvent l’influencer négativement. Transkribus rencontre peu de problèmes de césure de mots, de distinction entre majuscules et minuscules, de ponctuation, ainsi que de reconnaissance de caractères spéciaux et d’abréviations. Cependant, des difficultés surviennent lors de la détection d’espaces et de l’apprentissage de différentes orthographes pour les mêmes mots (vnd/und, aus/auß…). Les noms propres (notamment les lieux et les personnes), les chiffres et les indications de date sont particulièrement sujets aux erreurs. La question des règles de transcription prédéfinies est alors cruciale. Pour la reconnaissance de l’écriture manuscrite, l’idéal est de rester aussi proche que possible de l’original. Dans le cas de Wagener, cela concerne, par exemple, la distinction entre les lettres I et J, la majuscule et la minuscule, ainsi que la ponctuation. Si des corrections doivent être apportées dans le cadre d’une édition critique, il est recommandé de les ajouter à une étape ultérieure pour éviter de risquer d’entraîner des erreurs dans Transkribus.
L’application antérieure du modèle Wagener sur d’autres manuscrits a permis une amélioration du modèle. Cependant, l’IA atteint rapidement ses limites, surentraînant le modèle et entraînant des taux d’erreur inexplicablement élevés dans les ensembles d’entraînement et de validation. Une amélioration supplémentaire du modèle précédent n’est donc plus possible. La question se pose alors de savoir dans quelle mesure ce surentraînement est spécifique au programme Transkribus ou s’il peut être attribué de manière générale à tous les systèmes de transcription manuscrite automatisée (HTR) pilotés par une IA.
Transkribus semble avoir joué un rôle de pionnier au cours de ces dernières années, mais il ne constitue pas la seule possibilité d’exploiter des documents historiques grâce à l’IA. Comme l’a déjà souligné Elpida Perdiki, il existe plusieurs alternatives au programme de reconnaissance manuscrite Transkribus. Outre l’application open-source eScriptorium, elle en mentionne d’autres : « python systems implémentés avec la bibliothèque TensorFlow, tels que Kraken, un système OCR pour les documents historiques, et Tesseract, le moteur OCR développé par Google et principalement utilisé dans de nombreux projets22 ». Il serait autant plus intéressant dans cette perspective, de faire une étude comparative entre ces différents outils d’HTR à partir d’une source manuscrite exemplaire.