
Introduction
Les récits de voyage, en particulier ceux relatant des voyages éducatifs, constituent des témoignages importants qui peuvent fournir des informations sur les expériences et la vie de leurs auteurs. Ils documentent les rencontres avec de nouveaux lieux et personnes, les coutumes et les traditions, offrant ainsi un aperçu de l’appropriation mentale et matérielle ainsi que du traitement de l’étranger. Ils éclairent ainsi les processus de formation de soi et de la personnalité, souvent négligés jusqu’à présent par la recherche sur les témoignages personnels2. Particulièrement pour l’époque moderne, de vastes collections de cette catégorie de sources n’ont pas encore été suffisamment explorées ou analysées, telles que celles conservées à la Bibliothèque Herzog August de Wolfenbüttel3. Le projet d’édition « Grand Tour digital. Digitalisierung, Erschließung und Visualisierung frühneuzeitlicher Selbstzeugnisse von Bildungsreisen unter Anwendung teilautomatisierter Editionsverfahren » (Grand Tour digital. Numérisation, exploration et visualisation de témoignages personnels de voyages éducatifs de l’époque moderne en utilisant des procédés d’édition partiellement automatisés) part de ce problème fondamental et tente, comme le suggère déjà le titre complet, d’explorer également de nouvelles voies méthodologiques dans l’édition numérique en appliquant des procédures éditoriales partiellement automatisées4. Cela englobe d’une part l’utilisation de la reconnaissance automatique de l’écriture manuscrite (Handwritten Text Recognition, HTR) avec le programme Transkribus5, et d’autre part, le traitement et la mise en évidence des textes identifiés avec des outils logiciels de reconnaissance des entités nommées (Named Entity Recognition, REN). L’étape suivante est ensuite de créer une liaison des entités nommées identifiées avec des données normalisées et d’autres sources de données. Pour ce deuxième aspect, la REN, les récits de voyage se prêtent particulièrement bien à l’étude de cas, car leur densité en termes de noms de personnes et surtout de noms de lieux est particulièrement élevée pour alimenter une base de données.
Fig. 1 : Les voyages du pharmacien en formation Wagener, 1652–1659.
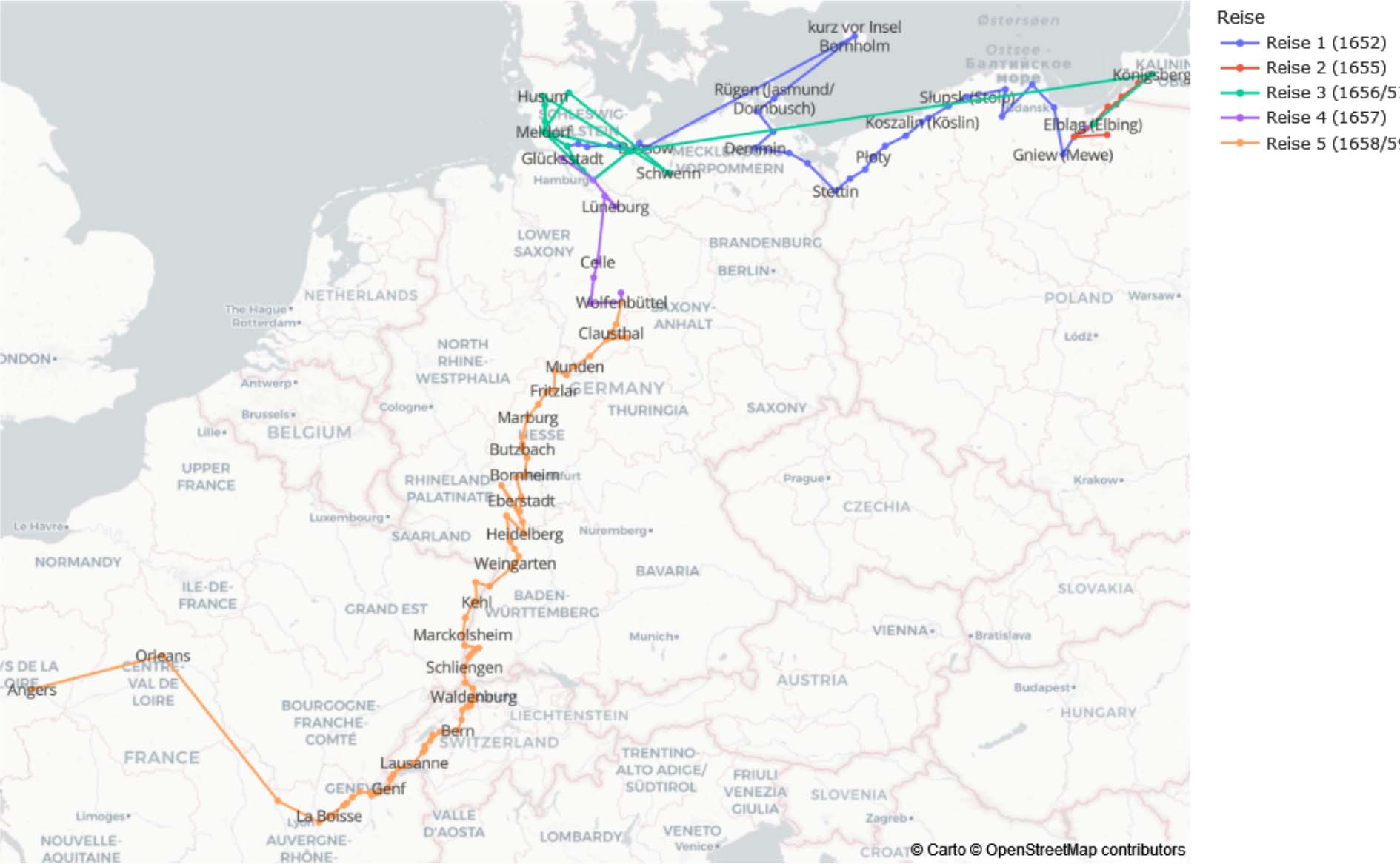
Ce type de travail sera montré à travers l’exemple d’un texte du projet « Grand Tour digital », rédigé par le jeune pharmacien Johannes Wagener entre 1652 et 16596. Wagener entreprit un voyage de compagnon (1652–1655), alors courant pour les futurs apothicaires à l’époque moderne7, ainsi qu’un voyage de formation (1658/59) en compagnie du duc Ferdinand Albrecht Ier de Brunswick-Wolfenbüttel-Bevern (Fig. 1)8. Le premier voyage le conduisit à travers le nord de l’Allemagne jusqu’à Königsberg en Prusse (aujourd’hui Kaliningrad), tandis que le second le mena à travers l’ouest et le sud de l’Allemagne, ainsi que la Suisse, jusqu’en France, où il décéda en 1659 à Angers des suites d’une fièvre ardente (« hitzigen Fieber »)9. Parallèlement, il entreprit également plusieurs voyages plus courts vers 1656/57, notamment au château de Gottorf, où il visita son célèbre cabinet de curiosités et put voir ainsi le globe géant qui s’y trouvait10. L’ampleur des informations géographiques, sociales et linguistiques du texte de Wagener ouvre de vastes possibilités, voire des défis, dans l’utilisation des méthodes de reconnaissance des entités nommées (REN) et dans le traitement des textes de voyage de l’époque moderne. Celles-ci seront retracées ci-après en se basant sur les expériences et le flux de travail du projet « Grand Tour digital ».
Situation de départ
Tout d’abord, partons d’une définition générale : « La reconnaissance d’entités nommées (REN) désigne la détection des noms propres (entités nommées) dans les textes, ainsi que leur classification en différents types d’entités. […] par défaut, les personnes, les lieux et les organisations font partie de ces types d’entités »11. Il existe fondamentalement deux types de méthodes qui sont utilisées à cet effet : des approches basées sur des règles ou des connaissances, reposant par exemple sur des vocabulaires contrôlés ou des gazetteers (index géographique), et des approches basées sur l’apprentissage automatique. Ainsi, la REN peut être associée de manière similaire à la reconnaissance d’écriture manuscrite dans le vaste domaine de l’apprentissage automatique et de l’intelligence artificielle, auquel appartiennent également des outils tels que Chat-GPT, actuellement très populaires12.
Contrairement aux grands modèles de langage (Large Language Models, LLM) avec des millions à des milliards de tokens et de paramètres, sur lesquels reposent Chat-GPT et d’autres outils de traitement du langage naturel pour les langues actuelles, les modèles correspondants et les ensembles de données disponibles pour les textes anciens sont beaucoup plus rares et plus petits. Ainsi, Ehrmann et al., dans un état des lieux récemment publié sur la REN dans de tels documents ont identifié 22 corpus annotés avec des données d’entraînement par rapport à 121 corpus pour les langues contemporaines13. Les données d’entraînement correspondent au corpus choisi pour étalonner la recherche et permettre ensuite au modèle de fonctionner. De plus, les modèles linguistiques pour les textes anciens, en raison de leur taille plus réduite et des défis spécifiques des stades linguistiques antérieurs sur lesquels nous reviendrons plus en détail, présentent généralement une fiabilité moindre (score F1 : 60-70 %) par rapport à ceux pour les langues actuelles (score F1 : généralement supérieur à 90 %)14. Bien entendu, même parmi eux, d’importantes différences subsistent en fonction des domaines spécifiques15.
La situation en ce qui concerne la REN dans les textes anciens est donc certainement perfectible, mais il y a eu ces dernières années plusieurs initiatives et projets qui utilisent notamment des éditions numériques pour générer des ensembles de données d’entraînement correspondants. On peut citer, par exemple, le projet NERDPool en cours depuis 2020, porté par l’Académie autrichienne des sciences ainsi que les universités d’Innsbruck et de Graz, qui a rassemblé des ensembles de données d’entraînement pour la REN en allemand ancien à partir de six collections de textes ou éditions allant du xvie au début du xxe siècle16. En outre, il existe des projets plus modestes, tels que ceux réalisés dans le cadre de mémoires de master ou de séminaires pratiques, où ont été élaborées des données d’entraînement grâce à de tels modèles et des tutoriels pour la REN dans les textes anciens17. Il s’agit donc d’un domaine de recherche extrêmement dynamique, particulièrement pour les sources du début de l’allemand contemporain et grâce aux récits de voyage18.
Workflow et problèmes actuels
Dans ce contexte globalement positif, nous avons commencé à élaborer un travail pour la REN qui fait suite à l’établissement du texte intégral avec Transkribus. Tout a commencé par le choix d’un outil approprié pour la REN, avec l’évaluation de trois candidats au total : Stanford Named Entity Recognizer19, WebLicht20 et la bibliothèque Python appelé spaCy21. Les trois outils sont basés sur des systèmes techniques spécifiques, offrant chacun des avantages et des inconvénients ainsi que des approches différentes pour relever les défis des textes de cette époque et de leur édition numérique. Avec WebLicht, une sorte de boîte à outils en ligne pour le traitement du langage naturel (NLP), il est par exemple possible de compenser la variation linguistique des textes anciens par rapport à l’allemand moderne en normalisant les textes avant la REN à l’aide d’un outil spécialisé22. Une autre approche pour adapter le logiciel au matériel textuel ancien et à ses particularités consiste à former ses propres modèles de REN à l’aide de l’apprentissage automatique. Cette méthode est possible à la fois avec le Stanford Named Entity Recognizer et avec spaCy. Cependant, avec le Stanford Named Entity Recognizer, ainsi qu’avec WebLicht, il est relativement complexe et fastidieux de traiter les données de transcription disponibles en TEI-XML23, notamment pour que les annotations déjà effectuées restent telles quelles et que le résultat en sortie soit à nouveau en XML et conforme à la norme TEI de manière à inclure les entités reconnues et annotées par le programme. C’est pourquoi le choix s’est finalement porté sur spaCy, car grâce à cet outil il est non seulement relativement facile et rapide de mettre en œuvre un flux de travail pour la REN, mais aussi parce que la plupart des projets ayant travaillé sur l’application de la REN aux éditions numériques ont utilisé spaCy24. Les solutions aux problèmes déjà développées et documentées, sur lesquelles nous reviendrons plus tard, peuvent être réutilisées, ce qui non seulement représente un gain de temps considérable, mais est également conforme à une pratique de recherche durable dans le domaine de l’édition numérique.
SpaCy est une bibliothèque Python open source dédiée au traitement du langage naturel (NLP). En plus d’une gamme complète de scénarios d’utilisation en linguistique informatique (comme la tokenisation, la segmentation de phrases, le marquage grammatical), la bibliothèque comprend également des composants pour la REN et offre la possibilité de former des modèles personnalisés à cet effet. Parallèlement, ces modèles basés sur l’apprentissage automatique peuvent être combinés avec des listes de mots et des motifs de reconnaissance d’entités, intégrant ainsi une approche basée sur la connaissance ou sur des règles. Ses nombreuses fonctionnalités et sa facilité d’utilisation relative ont conduit, comme mentionné précédemment, à son utilisation dans plusieurs projets liés aux éditions numériques pour la NER. De là sont également nés quelques packages Python pour l’extraction de données à partir de textes annotés en TEI et pour l’intégration des résultats d’analyse, notamment l’acdh-spacytei25 et le Standoff Converter26.
Avant même de choisir un outil de REN, la décision avait été prise de sélectionner un texte pour les essais et l’entraînement. Par souci de simplicité, les premières pages du compte rendu de voyage de Wagener ont été choisies, environ 20 pages qui devaient de toute façon être transcrites manuellement pour l’entraînement de Transkribus27. Ainsi, sans trop d’effort supplémentaire, il a été possible d’annoter les noms propres et les entités, formant ainsi la base de l’ensemble d’entraînement. Au total, 248 entités ont été étiquetées, dont 92 personnes, 148 lieux et 8 organismes. Il s’agit donc d’un ensemble d’entraînement relativement petit (en particulier pour les organismes), mais il semblait suffisant pour une première tentative et pour définir un modèle. Comme l’objectif initial était d’annoter le reste du compte rendu de voyage de Wagener avec cet ensemble, nous pouvions supposer que le matériel d’entraînement et le matériel cible présentaient une similarité suffisante pour obtenir des résultats acceptables.
Avant l’entraînement proprement dit, le texte devait être préparé d’une manière à pouvoir être traité. Ce fut le premier défi, car il s’est avéré initialement moins évident de convertir le texte TEI en un format JSON adapté à spaCy. En particulier, l’extraction de la position exacte des entités nommées s’est révélée initialement sujette à des erreurs en utilisant un script xslt, nécessitant ainsi un contrôle minutieux et chronophage28. Cependant, ce problème a pu être largement résolu en réutilisant des solutions et des packages de programmes existants provenant d’autres projets, comme mentionné précédemment. Après l’élaboration du flux de travail à partir d’un tutoriel d’Isabel Hansen issu de son mémoire de master rédigé à l’Université de Trèves, il a été assez simple de travailler avec le package Python acdh-spacytei29, pour mettre le texte TEI dans la forme nécessaire pour l’ensemble d’entraînement. Ensuite, les données ont dû être divisées en ensembles d’entraînement, de validation et de test30.
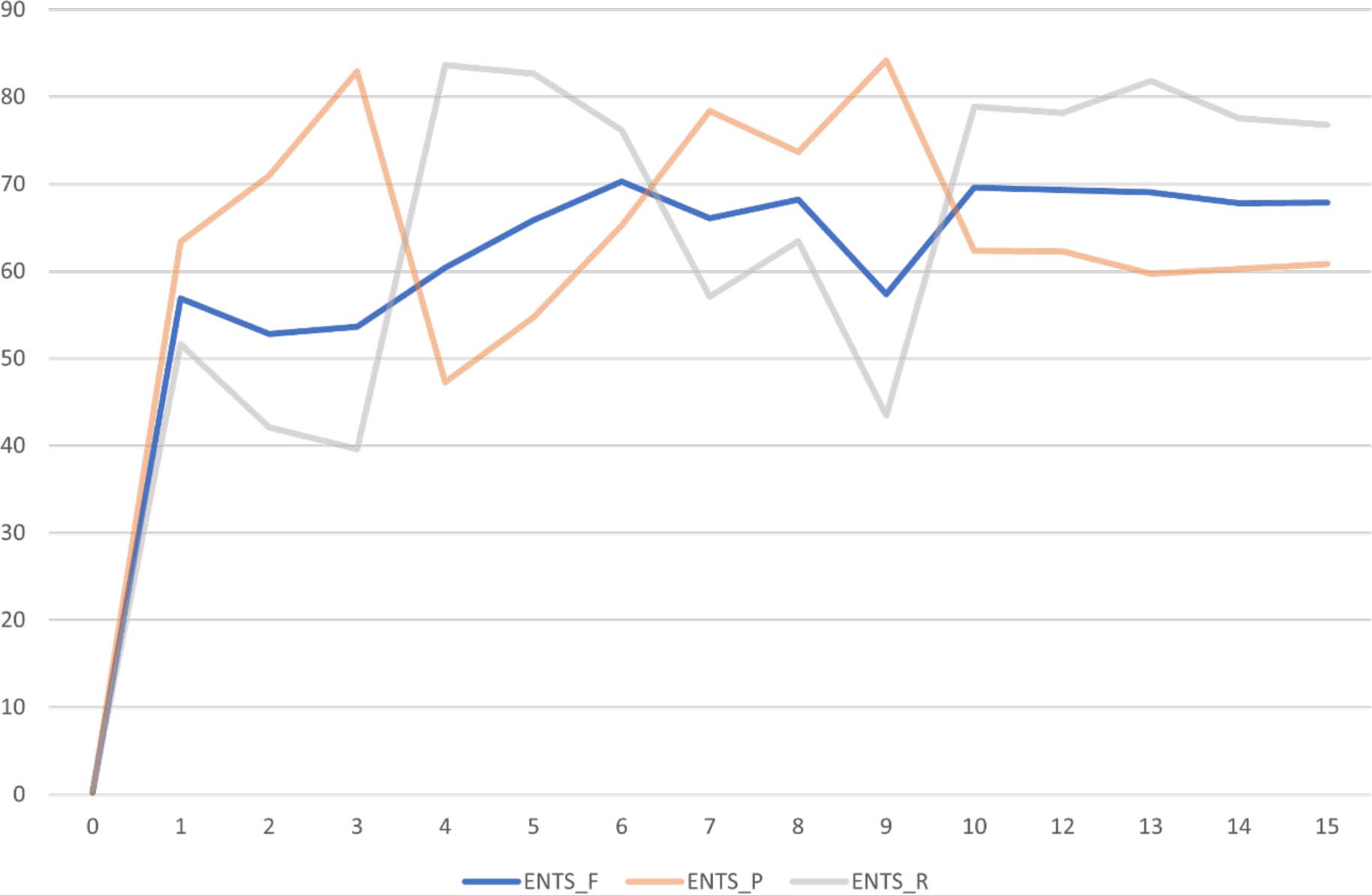
Ensuite, l’entraînement réel a eu lieu, ce qui peut parfois prendre beaucoup de temps. Au cours de plusieurs itérations, un réseau neuronal a été formé de manière à pouvoir prédire, en quelque sorte, quel mot ou quelle chaîne de caractères pouvait devenir une entité nommée. Cela se fait pratiquement par essais et erreurs, en attribuant d’abord aléatoirement des étiquettes aux entités nommées et en les comparant avec les annotations dans les données d’entraînement. Les erreurs qui surviennent sont mesurées et leur poids dans le réseau neuronal est ajusté en conséquence. Cela se poursuit jusqu’à ce qu’il n’y ait plus d’amélioration significative du modèle31. Les principales métriques utilisées pour évaluer ce processus sont la précision, le recall (rappel) et le score F1 calculé à partir de ceux-ci32. Un aperçu de l’évolution de ces métriques au cours de l’entraînement est facilement compréhensible dans spaCy grâce à une présentation sur un tableau simple. Pour une meilleure visualisation, le déroulement de l’entraînement peut également être représenté sous forme de diagramme, montrant comment le score F1 se stabilise progressivement autour de 70 (Fig. 2 et 3). Bien que cette valeur semble relativement basse à première vue, on ne peut pas attendre trop du modèle formé. Cependant, il se situe dans la fourchette de valeurs couramment rencontrées dans la littérature pour des ensembles de textes anciens. En tenant compte de la petite taille de l’ensemble d’entraînement, la performance est en elle-même relativement bonne.
Fig. 2 : Vue d’ensemble de spaCy dans l’entraînement d’un modèle REN. Représentation simplifiée dans un tableau.
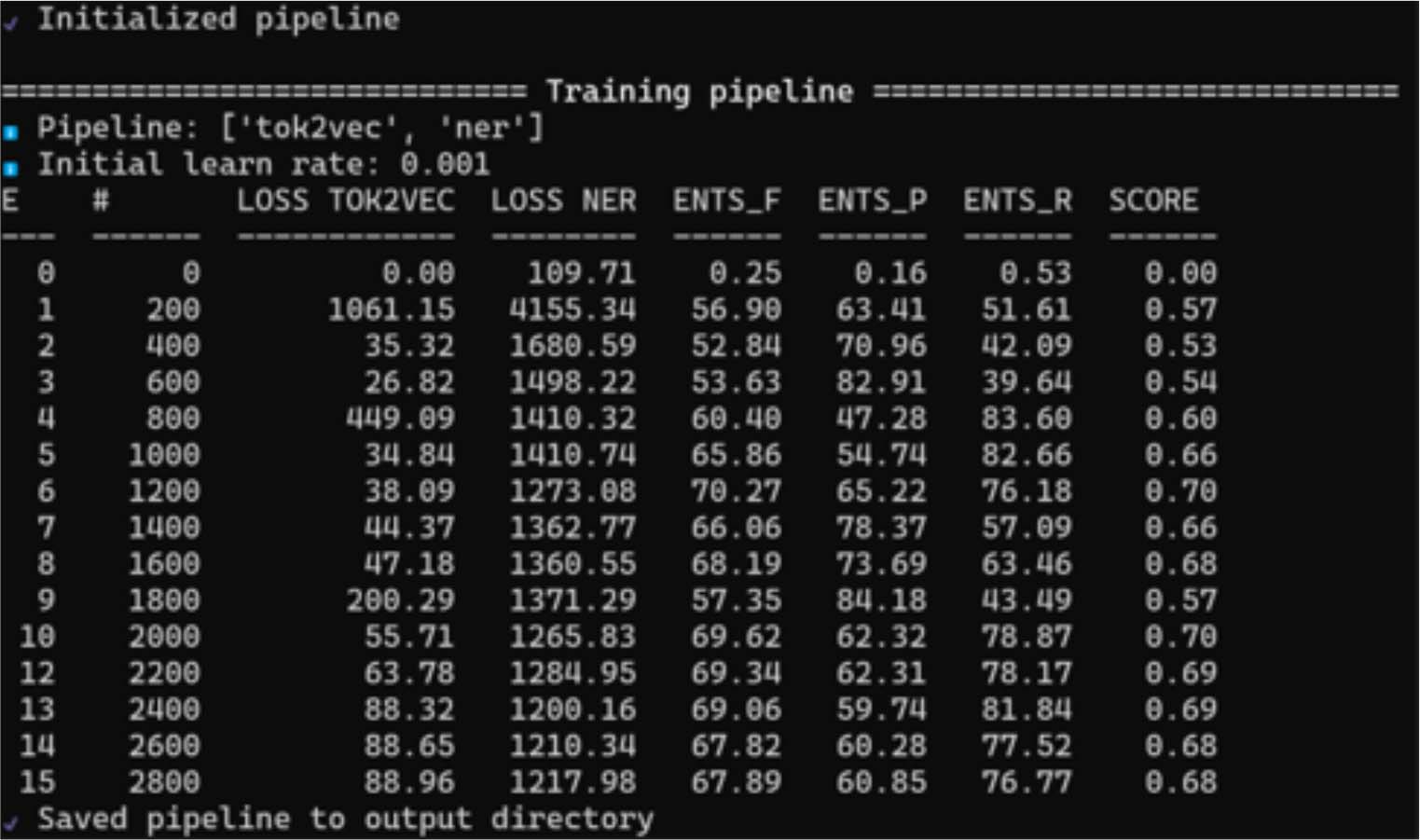
Fig. 3 : Visualisation des critères de qualité recall (ENTS_R), précision (ENTS_P) et f-score (ENTS_F) à partir du tableau ci-dessus au cours des itérations d’entraînement.
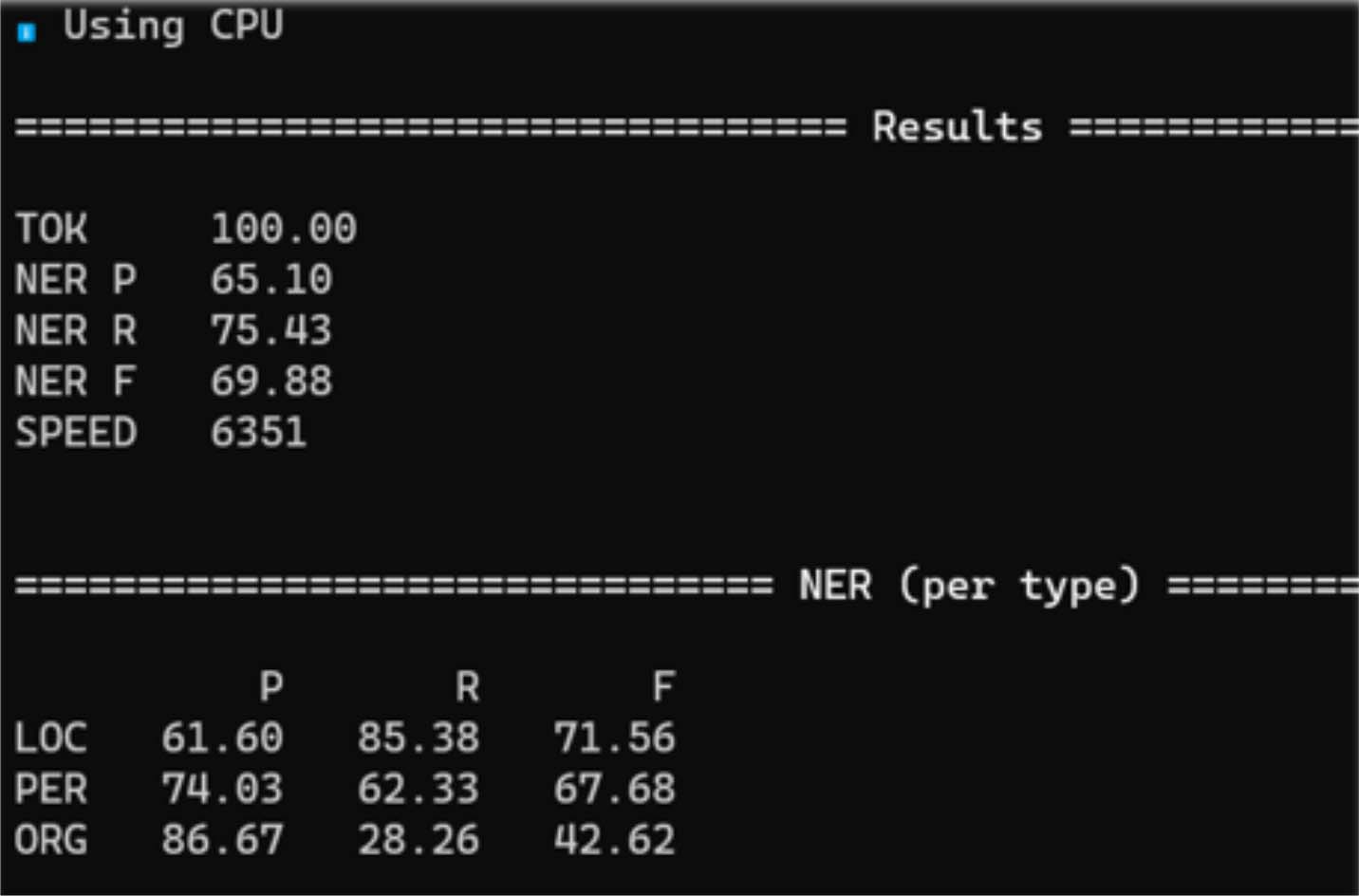
Une évaluation plus différenciée de la qualité du modèle peut se faire à l’aide des données du test. Il s’agit d’une partie des données annotées qui n’ont pas fait partie de l’ensemble d’entraînement. Avec elles, la précision, le recall et le score F1 peuvent être calculés pour un texte inconnu, permettant ainsi d’évaluer le modèle. Là encore, spaCy fournit les valeurs correspondantes, cette fois-ci détaillées par type d’entité. Elles peuvent ainsi être facilement comparées entre elles (Fig. 4). Pour les personnes et les lieux, les valeurs sont d’environ 70, donc dans la fourchette du modèle global. On observe que la reconnaissance des lieux fonctionne légèrement mieux. En revanche, les organismes obtiennent des résultats nettement moins bons. Cela est lié à leur nombre nettement inférieur dans les données d’entraînement, et même pour les lieux et les personnes, les différences peuvent probablement être attribuées à leur fréquence respective dans l’ensemble d’entraînement.
Fig. 4 : Vue d’ensemble de spaCy des résultats de validation du modèle REN entraîné.
Après l’entraînement et l’évaluation, le modèle peut être appliqué au texte non annoté. Un extrait du résultat est visible dans la Fig. 5, qui montre la vue HTML générée avec displaCy, un module correspondant de spaCy33. Nous pouvons utiliser un simple fichier texte comme base pour cela, et le fichier HTML pourrait également être utilisé pour créer une version TEI rudimentaire du texte. Cependant, comme une partie de la balise d’origine serait perdue, le Standoff Converter de David Lassner a été utilisé34. Avec le convertisseur, le texte brut peut être extrait du XML, traité avec spaCy, et les nouvelles annotations (par exemple, les entités nommées) peuvent être insérées dans le document source sans que le balisage d’origine soit perdu. Le résultat est visible dans la Fig. 6.
Fig. 5 : Sortie HTML du résultat des REN (conçu avec displaCy).

Fig. 6 : Sortie TEI du résultat des REN (conçu avec le Standoff-Converter).

Ainsi, on distingue ici un procès rudimentaire pour la REN dans les documents TEI, et le résultat est réutilisable et peut être appliqué aux textes que nous traiterons encore dans le projet. Cependant, il reste quelques problèmes ouverts et du travail à faire. Le plus grand problème est certainement que le taux de reconnaissance avec le modèle développé jusqu’à présent peut encore être amélioré. Cela est dû à la fois à la petite taille de l’ensemble d’entraînement, mais aussi aux particularités linguistiques des sources. Ils posent un défi aux outils de traitement automatique du langage naturel (NLP) qui sont conçus pour des langues contemporaines relativement normalisées. En effet, la langue au XVIIe et XVIIIe siècle présente de grandes variations orthographiques, des différences de vocabulaire, de morphologie et de structure syntaxique par rapport à l’allemand actuel. On trouve également dans les textes anciens un multilinguisme récurrent35. Quelques mots en latin, français, italien ou d’autres langues étaient généralement intégrés sans distinction typographique. Souvent, des passages entiers en une ou plusieurs langues étrangères étaient également intégrés dans un texte principalement allemand. Il s’agissait fréquemment de citations étrangères utilisées par les voyageurs qui se formaient à l’apprentissage des langues étrangères36. Surtout, les noms propres étaient régulièrement traduits dans d’autres langues, sans parler du fait qu’il n’y avait pas de conventions uniformes pour leur écriture, y compris chez un même auteur. Par ailleurs, l’utilisation de majuscules n’était pas appliquée de manière cohérente à cette époque37.
Cette incertitude sur les noms propres entraîne alors les deux autres problèmes : l’identification et la désambiguïsation des entités, ainsi que leur liaison avec des données normatives telles que Geonames38, GND39, VIAF40 ou encore Wikidata41. Pour ces raisons, on recueille souvent, en plus d’une entrée principale, des formes de noms historiques alternatives ou des formes dans d’autres langues. Une source de ces formes de noms peut être des éditions (numériques), ce qui nous amène à notre troisième point, « Perspectives ».
Perspectives
Quelles sont les solutions possibles pour les problèmes mentionnés ? Nous voyons surtout deux approches : l’élargissement de la base de données pour l’entraînement de modèles linguistiques historiques et la combinaison de ces modèles basés sur des algorithmes d’apprentissage automatique avec des approches basées sur des règles ou des connaissances. Pour cette dernière approche, il est nécessaire de développer des bases de données ou des gazetteers, comme c’est déjà partiellement le cas. Ils peuvent et doivent certainement être étendus et complétés dans certains domaines, ce qui justifie des éditions numériques annotées. Dans les lignes qui suivent, nous allons brièvement présenter nos expériences faites jusqu’à présent dans ce domaine du projet et esquisser les perspectives qui en découlent.
L’entraînement de la REN peut être adapté à l’élargissement de la base de données d’autant plus qu’il existe déjà des collections de données similaires qui peuvent potentiellement être réutilisées. Un exemple concret serait le projet NERDPool mentionné précédemment42. Cependant, les tentatives menées jusqu’à présent pour entraîner des modèles plus importants avec des éditions de la Herzog August Bibliothek n’ont conduit qu’à des résultats légèrement meilleurs pour la REN. En plus des problèmes déjà formulés inhérents aux sources, des défis supplémentaires sont apparus en raison d’approches éditoriales différentes en fonction des sources écrites43. Ces défis concernent les différentes pratiques de balisage par rapport aux entités nommées, les différents niveaux de normalisation du langage source et les différences en ce qui concerne la segmentation des textes, ce qui peut être intégré en tant qu’information contextuelle dans le modèle entraîné44. Cela rend nécessaire une adaptation partiellement manuelle des textes et de leur codage, ce qui représente une charge de travail non négligeable. Par conséquent, il semble judicieux de ne pas simplement intégrer de nombreux textes dans un ensemble d’entraînement, mais plutôt de créer des échantillons représentatifs et spécifiques au domaine (par exemple, des récits de voyage) codés selon des normes uniformes. De plus, il peut être utile de soumettre les données textuelles à d’autres opérations de traitement automatique du langage naturel avant l’entraînement, telles que la division en phrases individuelles. Cela peut également réduire le temps de calcul nécessaire pour créer un modèle.
Fig. 7 : Sortie HTML pour différents modèles NER avec et sans découpage de phrases.

Un contrepoint comparatif des résultats obtenus jusqu’à présent, qui intègre déjà en partie ces considérations, est visualisé dans la Fig. 7 avec displaCy. À gauche on trouve le modèle de base. Au milieu, c’est le modèle qui entraîne le texte de Wagener combiné avec des journaux du duc Auguste le Jeune de Brunswick-Wolfenbüttel45 et du prince Christian II d’Anhalt-Bernburg46. À droite, c’est un modèle basé sur Wagener et où le texte a de nouveau été divisé en phrases avec spaCy avant l’entraînement (ce qui repose bien sûr sur des modèles linguistiques pour des langues actuelles et est donc sujet aux erreurs correspondantes)47.
L’intégration de gazetteers et de modèles de reconnaissance pour la REN est relativement facile à faire dans spaCy. Il suffit de mettre les données correspondantes, par exemple les formes de noms de lieux, dans un format JSON simplifié basé sur des lignes et de les intégrer dans le pipeline de traitement. Théoriquement, il est possible de construire un flux de travail REN uniquement à l’aide d’une telle liste48. Il serait alors possible de comprendre et de contrôler ce qui est reconnu comme entité et ce qui ne l’est pas. Ce n’est pas le cas avec les réseaux neuronaux auto-apprenants. Ils s’apparentent à une boîte noire à l’intérieur de laquelle même les développeurs ne peuvent pas regarder ou de manière très limitée. Il est aussi possible de réutiliser les ressources existantes telles que les éditions numériques. Et il est possible d’attribuer des identifiants, ce qui permet la liaison avec des registres et des données normatives déjà existants (Fig. 8). Cela permettrait également d’automatiser dans une certaine mesure le lien avec les entités nommées, qui doit suivre la REN lors de la création de l’édition numérique49.
Fig. 8 : extrait d’un fichier JSONL avec les modèles et notions pour la REN.

Les différentes formes de noms induisent l’essentiel des inconvénients. Dans la mesure où les personnes n’apparaissent souvent que dans des contextes spécifiques et où la variabilité des noms est encore plus élevée, il semble judicieux d’interroger des termes fixes surtout pour les lieux et les organismes, qui sont plus ou moins des entités de longue durée. Mises à part quelques personnalités importantes (Jésus-Christ, Luther, Calvin, Charlemagne etc.), il est plus judicieux pour les personnes de définir des modèles plus généraux, comme avec « Kurfürst von… » (prince-électeur de…). Cependant, pour les membres de la haute noblesse ou les souverains, le problème des entités dites « imbriquées » se pose souvent, où une partie du nom peut être simultanément un toponyme50. De plus, les indications de lieu peuvent être relatives à l’emplacement de l’écrivain et donc être fortement dépendantes du contexte, de sorte que des mots tels que « ici », « en cet endroit », « là-bas » peuvent déformer la REN s’ils ne sont pas éliminés de la base de données. Il en va de même pour les pronoms personnels, qui peuvent également faire référence de manière contextuelle aux personnes. Malgré ces inconvénients, l’utilisation de gazetteers ou de listes de données peut améliorer de manière décisive la REN, en particulier lorsque peu de données d’entraînement sont disponibles.
Conclusion
Il est devenu évident que la REN est une composante exigeante mais judicieuse de la boîte à outils offerte par le traitement automatique du langage naturel pour l’élaboration d’éditions numériques. Cependant, il est important d’éviter la fausse allégation répandue selon laquelle « Big Data supposedly lets you get away with dirty data »51. Bien que nous ayons besoin de plus de données pour l’entraînement des modèles linguistiques anciens, notamment ceux de la REN, cela ne signifie pas nécessairement l’usage de big data. Des échantillons judicieusement choisis et soigneusement organisés devraient conduire à de bons résultats. Cela ne rend pas l’éditeur et le chercheur humains superflus, mais cela leur apportera un soutien significatif dans un avenir proche.
En outre, les problèmes liés à la REN ne doivent pas être considérés de manière isolée. Ils sont notamment liés à la modélisation des données et à l’enrichissement sémantique des éditions numériques, en particulier dans le domaine des récits de voyages anciens. Les défis mentionnés précédemment lors de la conversion des données textuelles et d’annotations vers et depuis le TEI-XML illustrent cette complexité. Ces problématiques prennent une place encore plus importante dans le cadre du développement d’ontologies visant à modéliser les relations entre les entités présentes dans les récits de voyages, ainsi que dans la création de jeux de données Linked Open Data réutilisables à partir d’éditions numériques. Ces efforts sont actuellement au cœur du projet de Ratisbonne, « Digitale Editionen Historischer Reiseberichte52 » (DEHisRe, Édition numérique des récits de voyage historiques), et démontrent que des travaux de recherche sur la REN dans les récits de voyages sont essentiels pour la création d’éditions numériques fiables. Ces efforts soulignent la pertinence de la reconnaissance des entités nommées (REN) dans le domaine de l’édition numérique. Il est évident que la question de la REN dans les récits de voyages historiques constitue actuellement un domaine de recherche très dynamique.