
Réalisation Christine Chadier , CC-BY-NC-SA
Depuis la mise en place du pôle d’histoire numérique (devenu Axe de recherche en histoire numérique) le Laboratoire de recherche historique est résolument tourné vers l’interopérabilité et l’accessibilité des données, une dizaine d’années avant même que le « FAIR1 » et l’Open Science ne deviennent une recommandation du CNRS. Dans ce cadre, pour les projets d’édition de sources, nous avons cherché un outil qui permette le traitement numérique de l’édition de texte. Nous avons choisi d’utiliser la TEI, Text Encoding Initiative, pour les grandes possibilités de balisage structurel et sémantique qu’elle offre, mais aussi parce qu’elle reste lisible par l’œil humain et, tant pour faciliter la saisie en TEI que le travail sur des corpus de textes qui nécessitent l’utilisation de schémas pour contrôler l’édition, nous avons retenu l’éditeur xml Oxygen, assez souple pour être indifféremment utilisé par les chercheurs et les ingénieurs mais permettant aussi d’assurer un traitement affiné des données.
La TEI a été mise en place en 1987 par trois sociétés savantes, l'Association for Computers and the Humanities, l'Association for Computational Linguistics et l'Association for Literary and Linguistic Computing. Depuis 1987, le modèle théorique original s’est adapté à différentes technologies. Le schéma TEI utilisé actuellement est la version P5 de 2007. Ce schéma xml-TEI2 est le fruit du travail de comités internationaux chargés notamment de la maintenance et la croissance du schéma, de rédiger la documentation, de développer des outils génériques, d’assurer le support sur des listes de diffusions et de faire connaître le format. La TEI permet de modéliser la structure d’un texte tel qu'il a été conçu ce qui est particulièrement précieux pour l’historien pour lequel la forme du texte peut se révéler aussi significative que son contenu. La TEI fournit un cadre pour penser la nature du texte. Le langage xml-TEI est aujourd’hui un standard en matière d’édition de textes et particulièrement d’édition de sources.
Pour essayer de résumer un langage aussi structuré et développé que la TEI 3en moins de 5 000 signes, retenons qu’il permet de rassembler dans un seul document :
les métadonnées dans le TEI Header
-
abstract,
-
idno identifiant standardisé
-
keywords
-
language
-
licence
-
profileDesc (fournit une description détaillée des aspects non bibliographiques du texte, notamment les langues utilisées et leurs variantes, les circonstances de sa production, les collaborateurs et leur statut)
-
publicationStmt (regroupe des informations concernant la publication ou la diffusion d’un texte électronique)
-
revisionDesc
-
titleStmt (regroupe les informations sur le titre d’une œuvre et les personnes ou institutions responsables de son contenu etc.)
et le texte lui-même (<text>) contenant un <front> (Titre, description du manuscrit, lieu de conservation, etc.) le <body>, structuré en éléments <div>. Chaque <div> peut contenir différents éléments textuels : liste (<list>), paragraphe (<p>), etc. La TEI permet non seulement d’attribuer à chaque élément <div> du <body> un identifiant unique mais aussi de les « typer » (fig. 1).
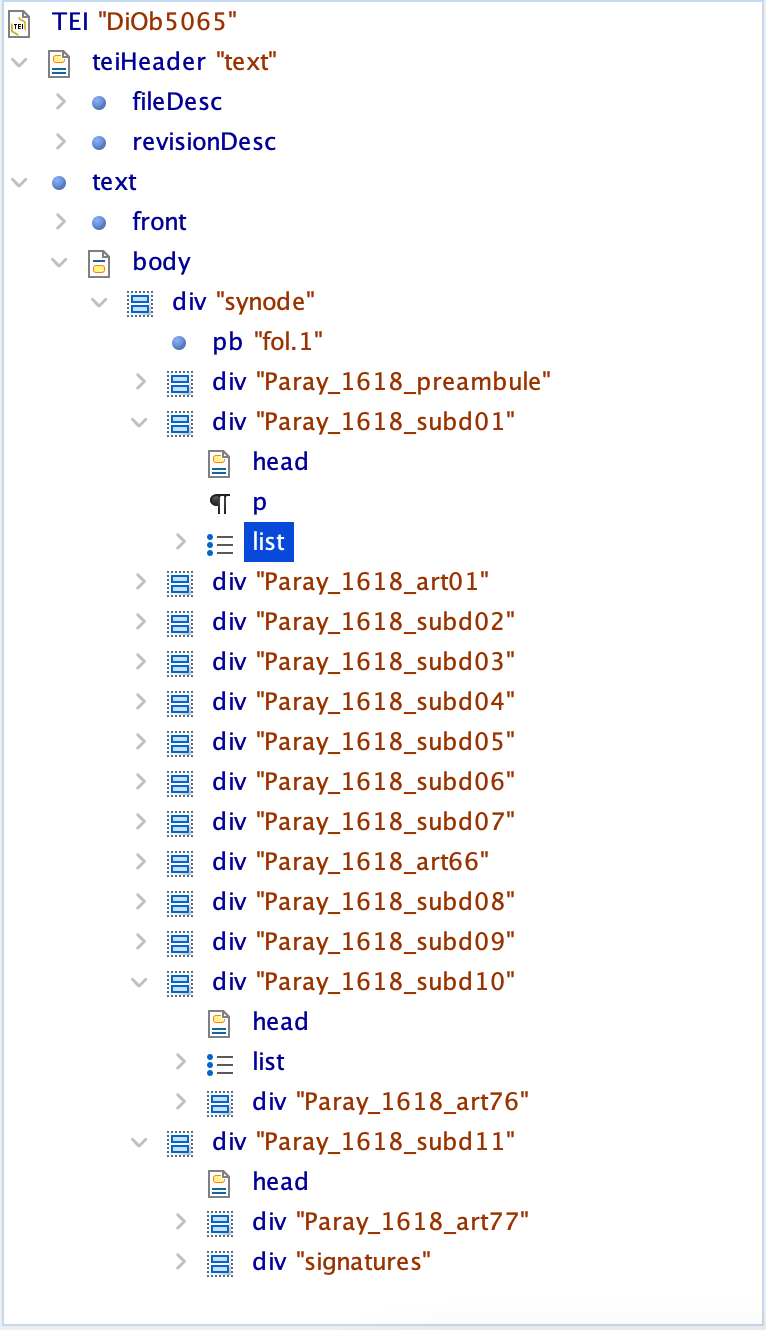
Fig 1 : Structure en xml TEI des actes du synode de Bourgogne de 1618 qui s’est tenu à Paray-le-Monial (capture d’écran Oxygen, éditeur xml)
Typer les éléments est particulièrement important lorsque l’on doit traiter un ensemble de textes (recueil d’actes, lettres, etc.), cela permet notamment de cibler les parties du texte sur lesquelles on souhaite effectuer une recherche textuelle (i. e. préambule, liste, signature, etc.) et l’identifiant unique permet de repérer instantanément la portion du texte concerné et ce quel que soit le langage utilisé pour effectuer les recherches. On pourrait par exemple écrire une requête en xslt pour lister des occurrences en fonction de l’identifiant attribué à une personne ou un lieu (i.e. rechercher les différentes graphies).
Pour mettre en place un projet d’édition de sources en TEI, il faut un chercheur qui prenne en compte l’intérêt de ce que le numérique peut apporter à sa recherche et un ingénieur pour organiser le travail. C’est cette collaboration étroite qui permet la réussite et la pérennité d’un projet.