
Attention, cette fiche est plutôt destinée aux services informatiques de votre plate-forme de revues.
Optimisation pour les moteurs de recherche
Afin d’être correctement référencé et mieux positionné dans les résultats d’une requête effectuée sur un moteur de recherche, il importe d’intégrer dans le code source de son site des balises HTML que les moteurs vont lire et dont la sémantique leur sera comprise.
Pour tout site, des balises meta comme :
meta name="description"
meta name="keywords"
meta name="author"
pourront être indexées et utilisées par les moteurs de recherche.
Exemple tiré d’un site Lodel : http://www.marievictoirelouis.net/index.php?id=47&auteurid=43

Ici, il n’y a que trois balises meta qui ne semblent pas correctement renseignées :
meta name="description" : contient ici les 300 premiers caractères de l’article au lieu d’un résumé.
meta name="keywords" : la balise est vide mais Google ne s’en sert pas.
meta name="author" : il aurait sans doute été légitime de considérer Hubertine Auclair comme auteure de l’article.
Pour des publications scientifiques, ces balises ne sont toutefois pas suffisantes. Il faut décrire les articles à l’aide de métadonnées en combinant des éléments puisés dans différents langages de description. Il existe cinq standard principaux dédiés à la description de publications scientifiques : Dublin Core, Highwire Press, Prism, Eprints et Be Press, ces deux derniers semblant beaucoup moins utilisés.
L’objectif d’être présent dans Google scholar impose de ne pas se contenter des très populaires balises Dublin Core :
« Google Scholar prend en charge les balises Highwire Press (par exemple, citation_title), Eprints (par exemple, eprints.title), BE Press (par exemple, bepress_citation_title) et PRISM (par exemple, prism.title). Utilisez les balises Dublin Core (par exemple, DC.title) en dernier recours – elles ne fonctionnent pas bien pour les articles de journaux car Dublin Core ne dispose pas de champs non ambigus pour le titre du journal, le volume, le numéro et les numéros de page. » Traduit avec www.DeepL.com/Translator (version gratuite)
https://scholar.google.fr/intl/fr/scholar/inclusion.html#indexing
Dublin core
Le Dublin Core est un langage de description de ressources numériques qui repose sur 15 éléments de base.
Exemple tiré d’un site Lodel : https://publications-prairial.fr/frontiere-s/index.php?id=1464
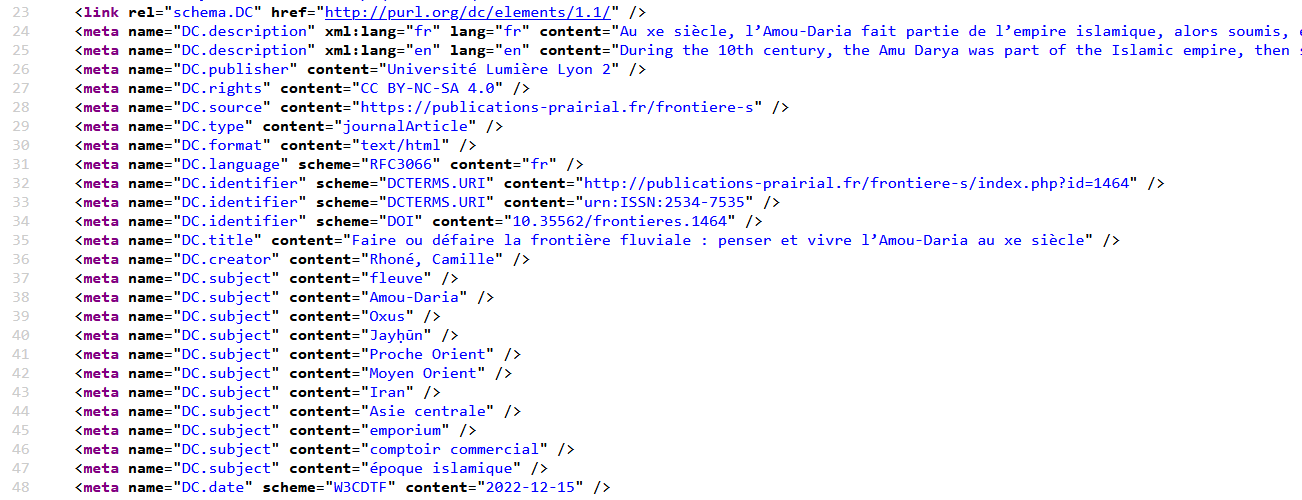
Dans l’exemple ci-dessus, les éléments du Dublin Core suivant ont été intégrés :
DC:description = résumé de l’article
DC:publisher = éditeur
DC:rights = licence creative commons utilisée
DC:source = url de la revue
DC:type = article de revue
DC:format = média permettant d’accéder à l’article
DC:language = langue de l’article
DC:identifier = DOI, ISSN
DC:title = titre de l’article
DC:creator = auteur de l’article
DC:subject = mots clés
DC:date = date de la publication
Highwire press
Exemple tiré de : https://www.erudit.org/fr/revues/sqrm/2010-v11-n1-2-sqrm04125/1054019ar/

Dans cet exemple figurent les éléments Highwire Press :
citation_title = titre de l’article
citation_journal_title = nom du journal d’où est issu l’article
citation_journal_abbrev = le nom abrégé du journal
citation_online_date = date de mise en ligne
citation_abstract_html_url = URL du résumé
citation_author = auteur de l’article
citation_author_institution = rattachement institutionnel de l’auteur de l’article
citation_language = langue d’écriture de l’article
citation_firstpage = première page de l’article
citation_lastpage = dernière page de l’article
citation_issn = ISSN papier et numérique
citation_volume = tomaison de la revue
citation_issue = numéro de la revue
citation_publication_date = date de parution
citation_publisher = éditeur de la revue
citation_doi = DOI de l’article.
Prism
Exemple tiré d’un site Lodel : https://journals.openedition.org/elseneur/289

Dans cet exemple, des éléments du schéma Prism ont été ajoutés aux métadonnées :
prism:url = URL de l’article
prism:publicationName = nom de la revue
prism:number = numéro de la revue
prism:issueName = titre spécifique du numéro
prism:startingPage = première page de l’article
prism:endingPage = dernière page de l’article
prism:publicationDate = date de la publication
prism:issn = ISSN de la revue
prism:eIssn = ISSN électronique de la revue
prism:teaser = résumé
Pour voir l’ensemble des éléments Prism : https://www.w3.org/Submission/2020/SUBM-prism-20200910/prism-basic.html#_Toc46322884
Eprints
Exemple tiré de : http://eprints.rclis.org/23244/
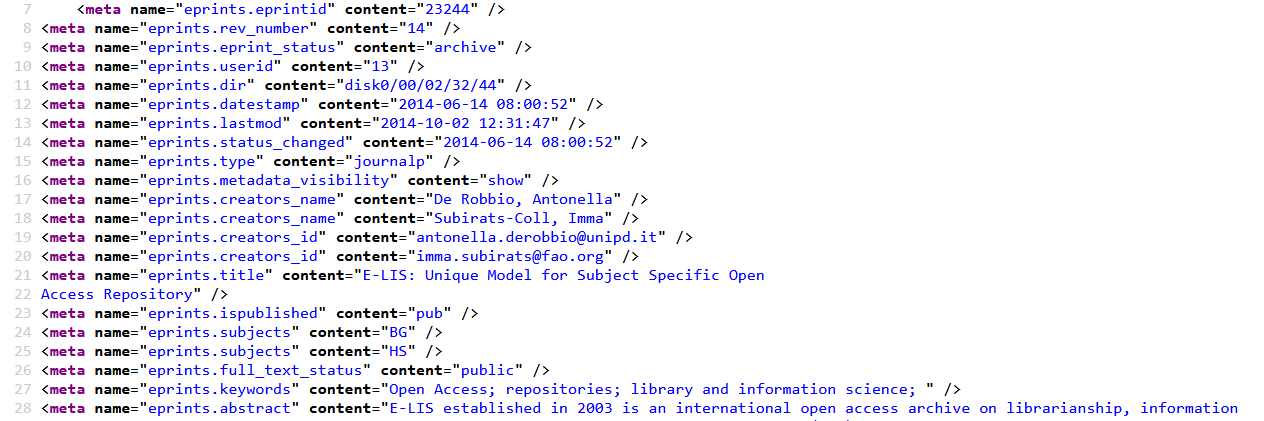
Dans cet exemple, des éléments du schéma Eprints ont été ajoutés aux métadonnées :
eprints.datestamp = date du dépôt
eprints.lastmod = date de dernière modification
eprints.type = article de journal
eprints.metadata_visibility = disponibilité des métadonnées
eprints.creators_name = nom de l’auteur
eprints.creators_id = adresse mail de l’auteur
eprints.title = titre de l’article
eprints.ispublished = publié ou non publié
eprints.subjects = catégories Repositories (HS) et Information dissemination and diffusion (BG)
eprints.full_text_status = disponibilité du texte intégral
eprints.keywords = mots clés de l’aricle
eprints.abstract = résumé de l’article
BE Press
Exemple tiré de : https://digitalcommons.unl.edu/usdaarsfacpub/1456/
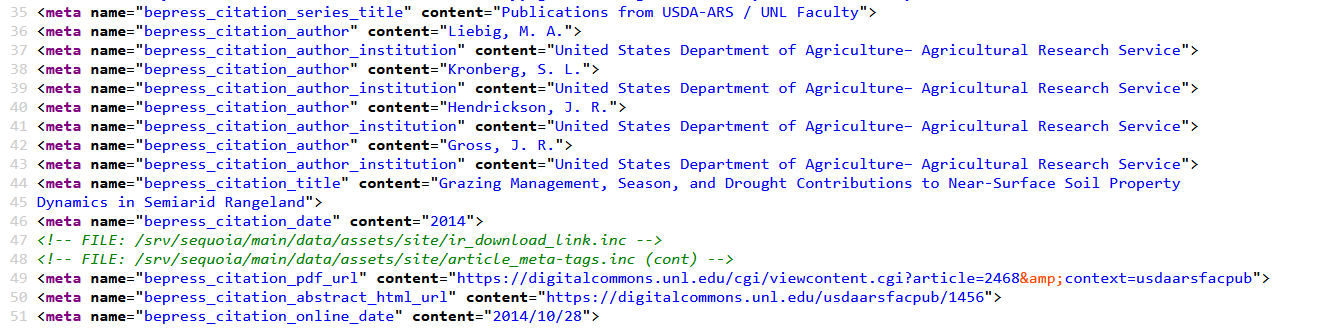
Dans cet exemple figurent les éléments Be Press :
bepress_citation_series_title = nom de la source de l’article
bepress_citation_author = auteur de l’article
bepress_citation_author_institution = rattachement institutionnel de l’auteur
bepress_citation_title = titre de l’article
bepress_citation_date = date de publication
bepress_citation_pdf_url = URL du pdf
bepress_citation_abstract_html_url = URL du résumé
bepress_citation_online_date = date de mise en ligne
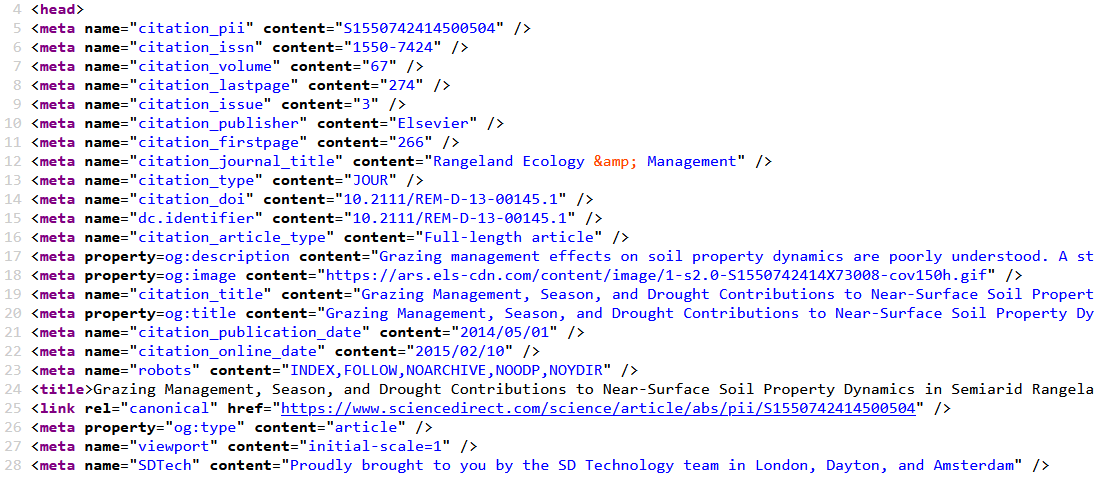
Publié initialement dans la revue Rangeland Ecology & Management, vol. 67, nº 3, p. 266-274, l’article, dans cette dernière édition, pourrait afficher les métadonnées Be Press suivantes :
bepress_citation_firstpage = 266
bepress_citation_lastpage = 274
bepress_citation_journal_title = Rangeland Ecology & Management
bepress_citation_volume = 67
bepress_citation_issue = 3
bepress_citation_doi = 10.2111/REM-D-13-00145.1
bepress_citation_issn = 1551-5028
bepress_citation_publisher = Elsevier.
On s’aperçoit effectivement que la plupart d’entre elles figurent selon le standard Highwire Press
Pour l’ensemble des balises Be Press : https://bepress.com/reference_guide_dc/metadata-options-digital-commons/
Pour connaître les correspondances entre les éléments issus de ces cinq schémas, consulter David I. Verrelli, Metadata tags for academic publications.
Optimisation pour Facebook
Open Graph est un protocole développé par Facebook afin d’optimiser le contenu de pages web et leur partage sur les réseaux sociaux. En l’absence de métadonnées Open Graph, c’est le robot de Facebook qui va extraire automatiquement des données pour produire un titre et une description, avec le risque d’erreur que cette méthode comporte. Il est donc recommandé d’ajouter des balises explicites.
Exemple tiré de : https://www.erudit.org/fr/revues/anthro/2021-v63-n1-anthro06140/1078580ar/

-
4 obligatoires :
og:url = url de votre article
og:type = le type de votre contenu. Pour nous, article
og:title = titre de votre article. Moins de 65 caractères pour éviter la troncature
og:image = url de l’image qui apparaît sur Facebook (le logo de votre revue, la vignette de votre numéro) -
D’autres recommandées :
og:description = résumé de votre article en moins de 300 caractères
og:locale = langue de la ressource, par ex : en_US, fr_FR
og:site_name = nom global de votre site web.
Retrouvez toutes les balises Facebook ici : https://developers.facebook.com/docs/sharing/webmasters
Optimisation pour Twitter
Les Twitter cards enrichissent vos tweets de métadonnées. Comme elles reposent sur le même protocole à l’œuvre dans Open Graph, si Twitter ne trouve aucune balise qui lui est propre, ce sont les données des balises Open Graph qui vont être affichées. Il n’est donc pas nécessaire de dupliquer les informations.
En premier lieu, il faut choisir une carte parmi les quatre modèles proposés : summary card (titre, description et vignette), summary card with large image (similaire à la précédente mais avec une image plus grande), app card (avec un téléchargement direct vers une application mobile) et player card (qui peut afficher une vidéo/un son/un média).
Exemple tiré de : https://www.erudit.org/fr/revues/anthro/2021-v63-n1-anthro06140/1078580ar/

Ensuite, on va ajouter des balises ad hoc :
twitter:card = type de la carte
twitter:site = nom du site web
twitter:title = titre du contenu en 70 caractères maximum
twitter:description = description du contenu en 200 caractères maximum
twitter:image = lien vers une image (formats JPG, PNG, WEBP et GIF) d’une taille inférieure à 5 Mo.
twitter:image:alt = la description de l’image en 420 caractères maximum
Retrouvez toutes les balises Twitter ici : https://developer.twitter.com/en/docs/twitter-for-websites/cards/overview/markup